Jak działają linki na stronach internetowych? Kompletny przewodnik po URL-ach i nawigacji w sieci
Dowiedz się, jak działają linki na stronach internetowych, zrozum budowę URL, rozwiązywanie DNS i techniczne aspekty nawigacji w sieci. Ekspercki przewodnik na 2025 rok.
Jak działają linki na stronach internetowych?
Linki na stronach internetowych działają na podstawie adresów URL (Uniform Resource Locators), które kierują przeglądarkę do konkretnych stron. Po kliknięciu linku lub wpisaniu URL, przeglądarka używa DNS do przetłumaczenia nazwy domeny na adres IP, następnie łączy się z serwerem i pobiera żądaną treść strony.
Zrozumienie linków i adresów URL na stronach internetowych
Linki na stronach internetowych są podstawowymi elementami nawigacji w sieci, umożliwiając użytkownikom płynne przemieszczanie się między stronami i zasobami w internecie. Link to w istocie adres URL (Uniform Resource Locator), który kieruje użytkownika do określonej strony w serwisie. Aby link działał poprawnie, adres URL musi zostać wpisany do przeglądarki dokładnie tak, jak jest podany, lub otwarty przez hiperłącze. Proces działania linków internetowych opiera się na współpracy wielu warstw technologii – od paska adresu przeglądarki po odległe serwery, na których znajduje się szukana treść.
Zrozumienie, jak działają linki, jest kluczowe dla osób zajmujących się tworzeniem stron, marketingiem internetowym czy afiliacyjnym. Po kliknięciu hiperłącza lub ręcznym wpisaniu adresu URL w pasek przeglądarki, w tle rozpoczyna się złożony ciąg zdarzeń. Przeglądarka musi rozpoznać używany protokół, odnaleźć właściwy serwer poprzez system DNS (Domain Name System), zażądać konkretnego zasobu i ostatecznie wyświetlić treść użytkownikowi. Cały ten proces trwa zwykle zaledwie kilka sekund, choć angażuje wiele komputerów i systemów komunikujących się przez internet.
Anatomia adresu URL: Rozkład budowy linku internetowego
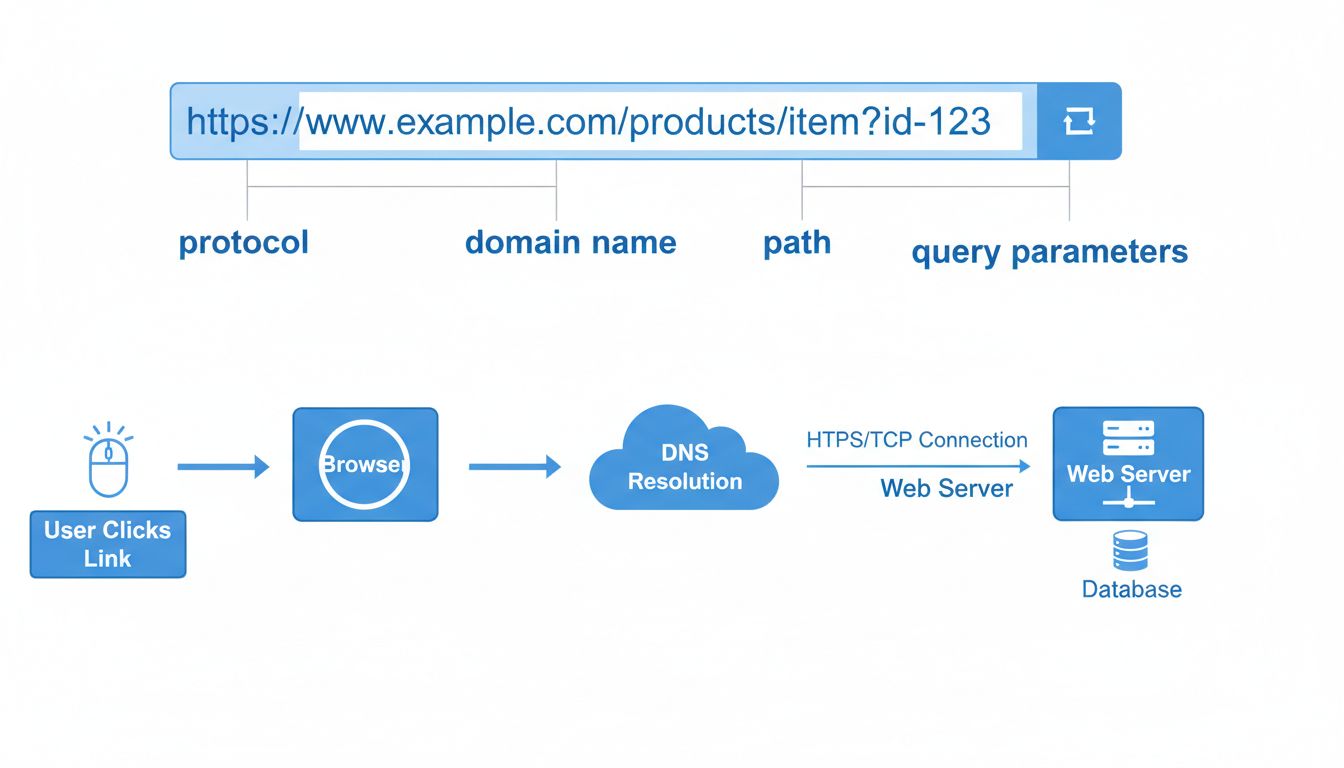
Adres URL składa się z kilku wyraźnych komponentów, z których każdy pełni określoną rolę w kierowaniu przeglądarki do właściwego zasobu. Zrozumienie tych elementów jest kluczowe, by pojąć, jak działają linki i dlaczego precyzja przy wpisywaniu adresów jest tak ważna. Podstawowa struktura URL wygląda następująco: protokół://subdomena.domena.rozszerzenie/ścieżka?parametry#fragment. Każdy z tych elementów odgrywa istotną rolę w procesie nawigacji, a brak lub błąd w którymkolwiek z nich może skutkować niedziałającym linkiem lub nieudaną próbą połączenia.
Element URL
Przykład
Cel
Protokół
https://
Określa metodę komunikacji (HTTP lub HTTPS)
Subdomena
www
Organizuje różne sekcje strony
Nazwa domeny
example
Unikalny identyfikator strony
Rozszerzenie (TLD)
.com
Domeny najwyższego poziomu, określające typ/kraj strony
Ścieżka
/products/item
Wskazuje dokładną lokalizację strony/zasobu
Parametry
?id=123&color=blue
Przekazuje dodatkowe dane do serwera
Fragment
#section-2
Kieruje do konkretnej sekcji na stronie
Protokół to pierwszy, kluczowy element każdego URL. HTTPS (Hypertext Transfer Protocol Secure) jest obecnie standardem dla nowoczesnych stron internetowych, zastępując starszy protokół HTTP. HTTPS szyfruje dane przesyłane między przeglądarką a serwerem, chroniąc wrażliwe informacje, takie jak hasła czy numery kart kredytowych, przed przechwyceniem. Symbol kłódki w pasku adresu przeglądarki oznacza, że połączenie jest bezpieczne i szyfrowane. Ta warstwa zabezpieczeń jest niezbędna dla sklepów internetowych, banków czy stron przetwarzających dane osobowe i finansowe.
Nazwa domeny to najbardziej rozpoznawalna część adresu URL, stanowiąca unikalny identyfikator strony. Składa się z domeny drugiego poziomu (np. “example”) oraz domeny najwyższego poziomu – TLD (np. .com, .org, .net). Subdomena, zwykle “www”, występuje przed nazwą domeny i pomaga w organizacji różnych sekcji serwisu. Niektóre strony wykorzystują niestandardowe subdomeny, np. “blog.example.com” czy “support.example.com”, by rozdzielić różne obszary funkcjonalne. Komponent ścieżki wskazuje dokładną lokalizację zasobu na serwerze, wykorzystując ukośniki podobnie jak struktura folderów na komputerze.
Uruchom swój program partnerski już dziś
Skonfiguruj zaawansowane śledzenie w kilka minut. Karta kredytowa nie jest wymagana.
Jak działają linki na stronach internetowych: Proces krok po kroku
Po kliknięciu hiperłącza lub wpisaniu adresu URL w pasek przeglądarki, uruchamia się zaawansowany proces obejmujący współpracę wielu systemów. Zrozumienie tego procesu pozwala pojąć, dlaczego linki działają właśnie tak i skąd biorą się typowe błędy. Cała droga od kliknięcia do wyświetlenia strony trwa zwykle zaledwie kilka sekund, choć składa się z kilku etapów, które muszą zadziałać idealnie.
Krok 1: Działanie użytkownika i analiza URL – Proces zaczyna się, gdy klikniesz link lub ręcznie wpiszesz adres URL do przeglądarki. Przeglądarka natychmiast rozkłada URL na części składowe: protokół, nazwę domeny, ścieżkę, parametry i fragmenty. Ten etap jest kluczowy, bo przeglądarka musi zrozumieć każdy element, aby wiedzieć, co zrobić dalej. Jeśli adres zawiera błędy składniowe lub niedozwolone znaki, przeglądarka może go odrzucić lub spróbować automatycznie poprawić.
Krok 2: Identyfikacja protokołu – Przeglądarka sprawdza, jaki protokół jest podany w URL (najczęściej HTTPS lub HTTP), aby ustalić, jak nawiązać połączenie z serwerem. Protokół określa zasady komunikacji między przeglądarką a serwerem. Połączenia HTTPS wymagają dodatkowych procedur bezpieczeństwa do ustanowienia szyfrowanego tunelu, podczas gdy HTTP jest prostszy, ale mniej bezpieczny. Współczesne przeglądarki coraz częściej ostrzegają użytkowników przed stronami bez HTTPS, promując w ten sposób bezpieczne połączenia.
Krok 3: Rozwiązanie DNS – To kluczowy etap w działaniu linków internetowych. Przeglądarka musi przetłumaczyć czytelną dla człowieka nazwę domeny (np. www.example.com
) na numeryczny adres IP, który rozumieją komputery. To tłumaczenie odbywa się przez system DNS, rozproszoną sieć serwerów utrzymującą ogromną bazę nazw domen i odpowiadających im adresów IP. Przeglądarka wysyła zapytanie DNS do resolvera, który przeszukuje hierarchię DNS, by znaleźć autorytatywny serwer nazw dla domeny. Po znalezieniu, resolver zwraca adres IP do przeglądarki. Proces ten trwa zwykle milisekundy, ale jest niezbędny do nawiązania połączenia.
Krok 4: Połączenie z serwerem – Mając adres IP, przeglądarka nawiązuje połączenie z serwerem, na którym znajduje się strona. W przypadku HTTPS odbywa się tzw. handshake TLS (Transport Layer Security), podczas którego przeglądarka i serwer wymieniają klucze kryptograficzne, by utworzyć bezpieczne połączenie. Handshake potwierdza tożsamość serwera za pomocą certyfikatów i zapewnia szyfrowanie całej dalszej komunikacji. Przy HTTP przeglądarka nawiązuje po prostu połączenie TCP do portu 80 serwera (lub 443 dla HTTPS).
Krok 5: Żądanie HTTP – Po nawiązaniu połączenia, przeglądarka wysyła żądanie HTTP do serwera, określając, który zasób chce pobrać. Zapytanie to obejmuje ścieżkę z URL, wszelkie parametry i nagłówki z informacjami o przeglądarce, preferowanym języku i inne metadane. Serwer odbiera żądanie i decyduje, który plik lub zasób odesłać przeglądarce.
Krok 6: Odpowiedź serwera – Serwer przetwarza żądanie i odsyła odpowiedź HTTP zawierającą żądany zasób. Odpowiedź obejmuje kod statusu (np. 200 – sukces, 404 – nie znaleziono, 500 – błąd serwera), nagłówki z metadanymi o treści oraz właściwą treść (HTML, CSS, JavaScript, obrazy itd.). Serwer może też ustawić ciasteczka lub inne informacje śledzące w nagłówkach odpowiedzi.
Krok 7: Renderowanie treści – Przeglądarka odbiera odpowiedź i zaczyna renderować treść. Parsuje HTML, by zrozumieć strukturę strony, stosuje style CSS do formatowania i wykonuje JavaScript dla interaktywności. Jeśli strona odwołuje się do zewnętrznych zasobów (obrazów, styli, skryptów), przeglądarka wykonuje kolejne żądania, aż wszystko zostanie załadowane i strona stanie się w pełni interaktywna.
Rozwiązanie DNS: Ukryty mechanizm działania linków internetowych
System nazw domenowych (DNS) to niewidzialna infrastruktura, dzięki której linki działają – tłumaczy on nazwy domen na adresy IP. Bez DNS użytkownicy musieliby zapamiętywać skomplikowane adresy numeryczne zamiast prostych nazw jak “example.com”. DNS działa jako hierarchiczny, rozproszony system z wieloma warstwami serwerów współpracujących, by rozwiązać nazwę domeny. Po wpisaniu adresu URL do przeglądarki natychmiast rozpoczyna się proces rozwiązywania DNS, a przeglądarka nie może kontynuować, dopóki nie uzyska adresu IP.
Proces DNS angażuje różne typy serwerów. Przeglądarka najpierw kontaktuje się z resolverem rekurencyjnym, zwykle udostępnianym przez dostawcę internetu (ISP) lub publiczną usługę DNS, jak Google DNS czy Cloudflare DNS. Resolver rekurencyjny odpowiada za znalezienie odpowiedzi na zapytanie, sięgając po inne serwery, jeśli to konieczne. Jeśli nie ma odpowiedzi w swojej pamięci podręcznej, zwraca się do serwera nazw głównych (root nameserver), który kieruje go do odpowiedniego serwera TLD. Ten z kolei kieruje do autorytatywnego serwera nazw dla danej domeny, który ostatecznie zwraca adres IP. Cały ten proces, zwany rekurencją DNS, odbywa się transparentnie i zwykle trwa milisekundy.
Pamięć podręczna DNS (caching) odgrywa kluczową rolę w efektywnym działaniu linków. Po uzyskaniu adresu IP resolver przechowuje tę informację przez okres określony przez TTL (Time To Live) domeny. Dzięki temu nie trzeba za każdym razem wykonywać pełnego zapytania DNS, co znacznie przyspiesza łączenie się ze stroną. Przeglądarki utrzymują też własną pamięć podręczną DNS, podobnie jak ISP i inne resolvery w internecie. Ten wielopoziomowy system cache sprawia, że popularne strony są dostępne bardzo szybko, bez ciągłego odpytywania autorytatywnych serwerów nazw.
Dołącz do naszego newslettera
Bądź pierwszym, który dowie się o nowych funkcjach i aktualizacjach produktu.
HTTP i HTTPS: Protokoły napędzające działanie linków
Protokół wpisany na początku adresu URL decyduje o sposobie komunikacji przeglądarki z serwerem. HTTP (Hypertext Transfer Protocol) był pierwotnym protokołem komunikacji w sieci, ale przesyłał dane otwartym tekstem – każdy, kto przechwycił ruch, mógł odczytać wrażliwe informacje, np. hasła czy numery kart. HTTPS (Hypertext Transfer Protocol Secure) rozwiązuje ten problem, dodając warstwę szyfrowania przy użyciu certyfikatów SSL/TLS (Secure Sockets Layer/Transport Layer Security).
Po wejściu na stronę HTTPS, przeglądarka i serwer wykonują handshake TLS, by ustanowić szyfrowane połączenie. W trakcie tego procesu serwer przedstawia certyfikat cyfrowy, potwierdzający jego tożsamość i zawierający klucz publiczny. Przeglądarka weryfikuje autentyczność certyfikatu, sprawdzając go na liście zaufanych urzędów certyfikacji. Po pozytywnej weryfikacji przeglądarka i serwer uzgadniają klucz szyfrujący, który chroni całą dalszą komunikację. Dzięki temu nawet przechwycenie ruchu nie pozwoli odczytać przesyłanych danych.
Różnica między HTTP a HTTPS dotyczy nie tylko bezpieczeństwa – wpływa także na pozycjonowanie i zaufanie użytkowników. Google i inne wyszukiwarki faworyzują strony z HTTPS, a nowoczesne przeglądarki wyświetlają ostrzeżenia przy stronach korzystających z HTTP. Użytkownicy nauczyli się szukać symbolu kłódki w pasku adresu jako oznaki bezpiecznego połączenia i często opuszczają stronę, gdy widzą ostrzeżenia o braku zabezpieczeń. Dlatego HTTPS stał się standardem nie tylko dla stron przetwarzających dane wrażliwe.
Parametry URL i ciągi zapytań: Rozszerzanie funkcjonalności linków
Parametry URL, zwane też ciągami zapytań (query strings), pozwalają przekazywać dodatkowe informacje do serwera za pośrednictwem samego adresu. Pojawiają się po znaku zapytania (?) w URL i składają się z par klucz-wartość rozdzielonych znakiem “&”. Przykładowy adres wyszukiwania może wyglądać tak: https://www.example.com/search?q=linki+na+stronie&category=technologia&sort=relevance. Każdy parametr dostarcza serwerowi określonych informacji do personalizacji odpowiedzi.
Parametry URL pełnią wiele ważnych funkcji w działaniu linków. Wyszukiwarki wykorzystują je do śledzenia zapytań i filtrowania wyników. Sklepy internetowe stosują parametry do filtrowania produktów według kategorii, ceny czy innych cech. Platformy analityczne używają parametrów (np. UTM) do śledzenia skuteczności kampanii marketingowych. Parametry paginacji umożliwiają wyświetlanie dużych zbiorów danych na wielu stronach. Bez parametrów URL strony byłyby znacznie mniej elastyczne i trudniej byłoby personalizować treści czy śledzić zachowania użytkowników.
Jednak parametry URL mogą stwarzać wyzwania dla SEO i użyteczności. Wyszukiwarki mogą traktować adresy z różnymi parametrami jako osobne strony, co prowadzi do problemów z duplikacją treści. Zbyt długie adresy z wieloma parametrami są trudne do czytania i udostępniania. Dlatego współczesne praktyki webmasterskie preferują czystsze adresy oparte na ścieżkach, np. zamiast example.com/products?category=buty – example.com/products/buty. Niemniej jednak, parametry pozostają niezbędne dla treści dynamicznych oraz śledzenia.
Typowe błędy adresów URL i jak je naprawić
Zrozumienie działania linków to także świadomość, co może pójść nie tak. Najczęstszy błąd to 404 Not Found, pojawiający się, gdy serwer nie znajduje żądanego zasobu pod podanym adresem. Może do tego dojść, gdy strona została usunięta, przeniesiona pod inny adres lub adres zawiera literówkę. Inne popularne błędy to 403 Forbidden (brak uprawnień do zasobu), 500 Internal Server Error (nieoczekiwany problem po stronie serwera) oraz 502 Bad Gateway (nieprawidłowa odpowiedź od serwera pośredniego).
W przypadku niedziałającego linku warto wykonać kilka kroków diagnostycznych. Najpierw dokładnie sprawdź adres pod kątem literówek czy błędnej wielkości liter – adresy URL są wrażliwe na wielkość znaków, więc Example.com i example.com to nie zawsze to samo. Jeśli adres jest poprawny, spróbuj usunąć część ścieżki za nazwą domeny, aby sprawdzić, czy główna strona działa. Jeśli strona główna działa, ale podstrona nie, mogła zostać przeniesiona lub usunięta – wówczas możesz poszukać jej w wyszukiwarce lub spróbować znaleźć zaktualizowany adres.
Właściciele stron mogą zapobiegać błędom linków, wdrażając prawidłowe przekierowania przy zmianie adresów. Przekierowanie 301 (stałe) informuje wyszukiwarki i przeglądarki, że strona została trwale przeniesiona, zachowując pozycje w wyszukiwarkach i automatycznie przekierowując użytkowników. Przekierowanie 302 (tymczasowe) oznacza chwilową zmianę i nie przenosi autorytetu SEO. Dzięki strategicznemu wykorzystaniu przekierowań można utrzymać pozytywne doświadczenie użytkownika i pozycje nawet przy przebudowie serwisu.
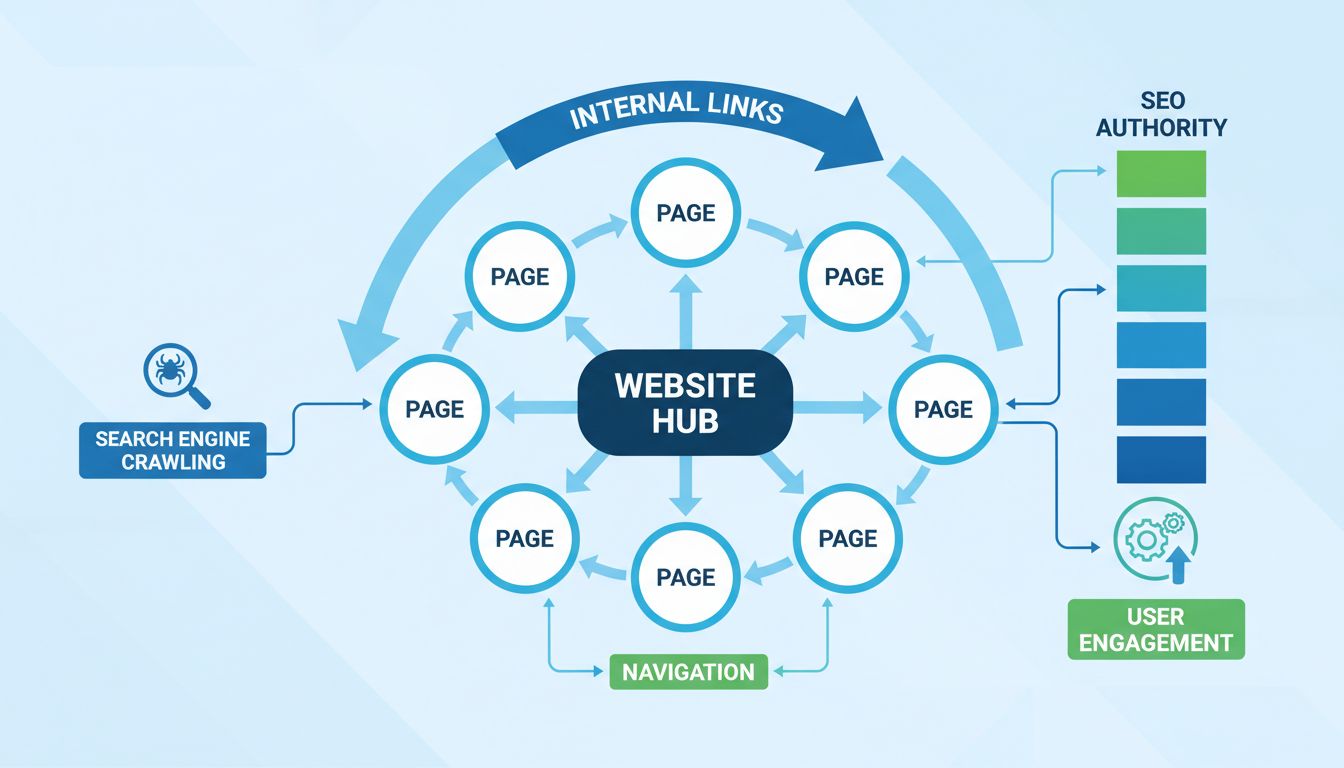
Najlepsze praktyki tworzenia adresów URL dla webdeveloperów i SEO
Tworzenie skutecznych URL-i wymaga zrozumienia zasad działania linków oraz uwzględnienia aspektów technicznych i doświadczenia użytkownika. Adresy powinny być opisowe i zawierać istotne słowa kluczowe, które wskazują na zawartość strony. Na przykład example.com/blog/jak-optymalizowac-linki-na-stronie jest znacznie bardziej informacyjny niż example.com/page123. Opisowe adresy pomagają zarówno użytkownikom, jak i wyszukiwarkom rozumieć zawartość strony, zwiększając współczynnik kliknięć z wyników i poprawiając udostępnialność w mediach społecznościowych.
Adresy URL powinny być jak najkrótsze, zachowując przy tym opisowość. Długie adresy są trudne do wpisania, zapamiętania i udostępnienia. Mogą być też obcinane w wynikach wyszukiwania czy w postach w social media. Do oddzielania słów w adresie najlepiej używać myślników, ponieważ wyszukiwarki traktują je jako separatory, a podkreślniki mogą być ignorowane. Zaleca się także stosowanie wyłącznie małych liter – niektóre serwery rozróżniają wielkość znaków w adresach.
Struktura adresów powinna odzwierciedlać logiczną organizację treści na stronie. Hierarchiczna struktura, np. example.com/products/elektronika/laptopy/laptopy-do-gier, jasno pokazuje zależności między sekcjami i pomaga użytkownikom zorientować się, gdzie się znajdują. Ułatwia to także wyszukiwarkom indeksowanie treści. Planując strukturę adresów, warto uwzględnić przyszły rozwój serwisu i projektować je tak, by pozostały aktualne i funkcjonalne wraz z rozbudową treści.
Zaawansowane pojęcia URL: Fragmenty, kotwice i deep linking
Fragmenty URL, oznaczane znakiem hash (#) i identyfikatorem, pozwalają linkom kierować do konkretnych sekcji na stronie. Przykładowo, example.com/article#section-2 wyświetli stronę i automatycznie przewinie ją do sekcji o ID “section-2”. Fragmenty są przetwarzane wyłącznie przez przeglądarkę po stronie użytkownika i nie są przesyłane do serwera, dzięki czemu poprawiają użyteczność bez potrzeby obsługi po stronie serwera. Wiele nowoczesnych stron wykorzystuje fragmenty do tworzenia płynnych aplikacji jednostronicowych (SPA), gdzie różne sekcje są dostępne bez pełnego przeładowania strony.
Linki kotwiczące (anchor links), tworzone za pomocą znaczników HTML z atrybutem ID, współpracują z fragmentami URL, umożliwiając precyzyjną nawigację wewnątrz strony. Po kliknięciu takiego linku lub wejściu na adres z fragmentem, przeglądarka automatycznie przewija do odpowiedniego elementu. Jest to szczególnie przydatne w długich treściach, takich jak artykuły, dokumentacje czy przewodniki, gdzie użytkownicy mogą chcieć przeskoczyć od razu do wybranej sekcji. Wyszukiwarki rozpoznają i indeksują linki kotwiczące, co pozwala wyświetlać bezpośrednie linki do fragmentów stron w wynikach, zwiększając współczynnik kliknięć i satysfakcję użytkowników.
Deep linking to praktyka linkowania bezpośrednio do konkretnej treści w serwisie zamiast do strony głównej. Takie linki są niezbędne dla dobrego UX i SEO, ponieważ umożliwiają użytkownikom szybki dostęp do poszukiwanej treści bez konieczności wielokrotnego klikania. Wyszukiwarki cenią strony z dobrze rozwiniętym deep linkingiem, bo świadczy to o dobrej organizacji informacji. Dla marketerów afiliacyjnych i twórców treści deep linking jest szczególnie ważny – pozwala kierować ruch do konkretnych produktów, artykułów czy zasobów najbardziej interesujących odbiorców.
Rola linków na stronach w marketingu afiliacyjnym i śledzeniu
Dla marketerów afiliacyjnych zrozumienie działania linków jest kluczowe dla skutecznego zarządzania kampaniami i monitorowania efektów. Linki afiliacyjne to specjalne adresy URL z parametrami śledzącymi, które identyfikują afilianta, kampanię i inne istotne informacje. Gdy użytkownik kliknie link afiliacyjny i dokona zakupu lub innego pożądanego działania, parametry śledzące pozwalają sieci afiliacyjnej przypisać konwersję do właściwego partnera i kampanii. To przypisanie jest niezbędne do naliczania prowizji i mierzenia skuteczności działań.
PostAffiliatePro, wiodąca platforma do zarządzania afiliacją, oferuje zaawansowane narzędzia do tworzenia, zarządzania i śledzenia linków afiliacyjnych. Platforma pozwala generować własne linki z wbudowanymi parametrami śledzącymi, monitorować kliknięcia i konwersje w czasie rzeczywistym oraz optymalizować kampanie na podstawie szczegółowej analityki. Rozbudowany system zarządzania linkami zapewnia precyzyjne śledzenie na wielu kanałach i urządzeniach, dostarczając afiliantom danych niezbędnych do maksymalizacji zarobków. Możliwość skracania linków sprawia, że są one łatwiejsze do udostępnienia w mediach społecznościowych i innych miejscach, przy pełnym zachowaniu funkcji śledzenia.
Zrozumienie struktury URL i parametrów jest szczególnie ważne dla afiliantów korzystających z PostAffiliatePro. Platforma umożliwia dostosowanie parametrów śledzących, by rejestrować szczegółowe dane o źródłach ruchu, kampaniach i zachowaniach użytkowników. Dzięki strategicznemu wykorzystaniu parametrów URL afilianci mogą segmentować ruch i określać, które kampanie i kanały są najbardziej zyskowne. Takie podejście, oparte na danych, pozwala stale optymalizować i poprawiać wyniki kampanii, co przekłada się na wyższe zarobki i lepszy zwrot z inwestycji.
Optymalizuj swoje linki afiliacyjne z PostAffiliatePro
Opanuj zarządzanie linkami i ich śledzenie z wiodącym oprogramowaniem afiliacyjnym. PostAffiliatePro zapewnia zaawansowane śledzenie URL, zarządzanie linkami oraz kompleksową analitykę, by zmaksymalizować skuteczność Twojego marketingu afiliacyjnego.
Dlaczego linki są ważne na stronie internetowej? Kompletny przewodnik SEO
Dowiedz się, dlaczego linki są kluczowe dla sukcesu strony. Poznaj, jak linki wewnętrzne i zewnętrzne poprawiają SEO, doświadczenie użytkownika i indeksowanie p...
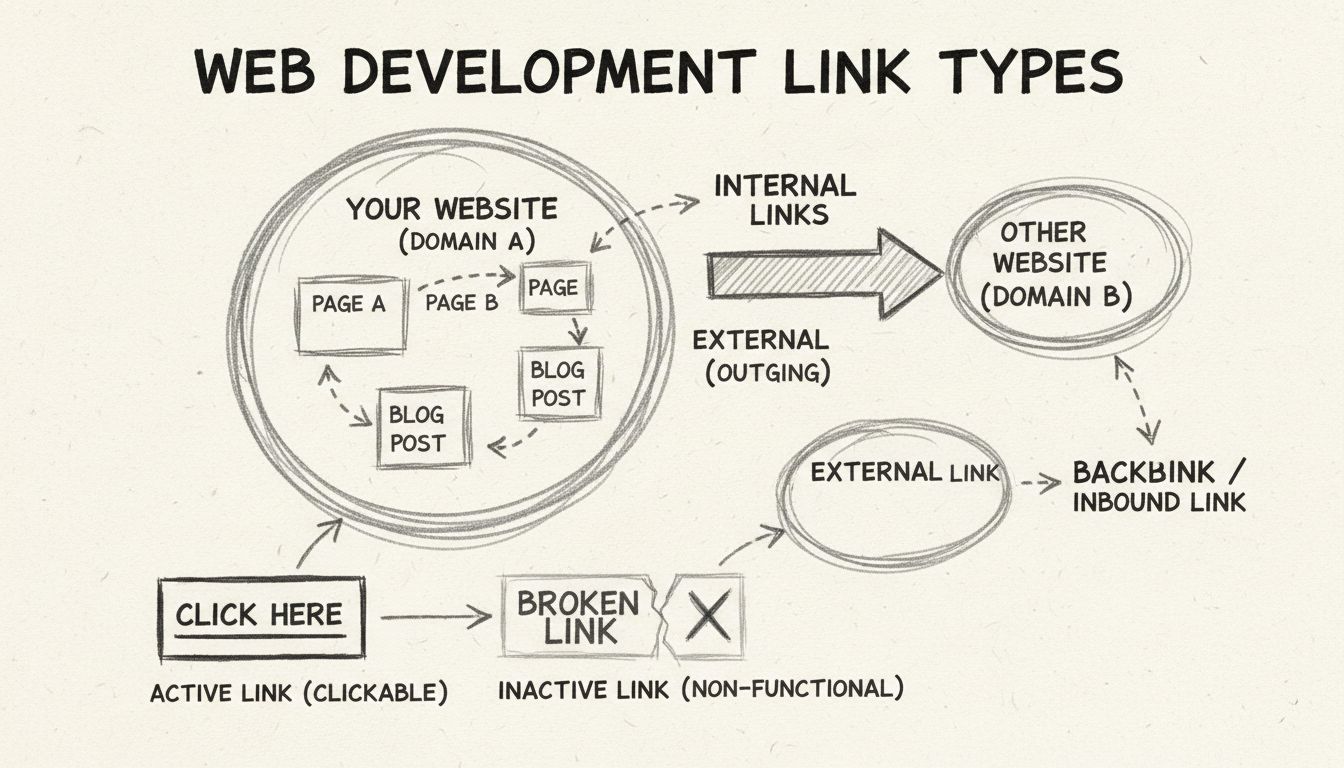
Rodzaje linków: Kompletny przewodnik po linkach wewnętrznych, zewnętrznych i backlinkach
Kompleksowy przewodnik po różnych typach linków, w tym linkach wewnętrznych, zewnętrznych, backlinkach, linkach aktywnych, nieaktywnych, dofollow, nofollow i in...
10 min czytania
Będziesz w dobrych rękach!
Dołącz do naszej społeczności zadowolonych klientów i zapewnij doskonałą obsługę klienta dzięki PostAffiliatePro.