
Wyszukiwarka
Wyszukiwarka to oprogramowanie stworzone, aby ułatwić użytkownikom wyszukiwanie w internecie. Przeszukuje miliony stron i dostarcza najbardziej trafne wyniki....
4 min czytania
SearchEngine
SEO
+3
Dowiedz się, jak identyfikować roboty wyszukiwarek za pomocą ciągów user-agent, adresów IP, wzorców żądań i analizy zachowań. Niezbędny przewodnik dla webmasterów i deweloperów.
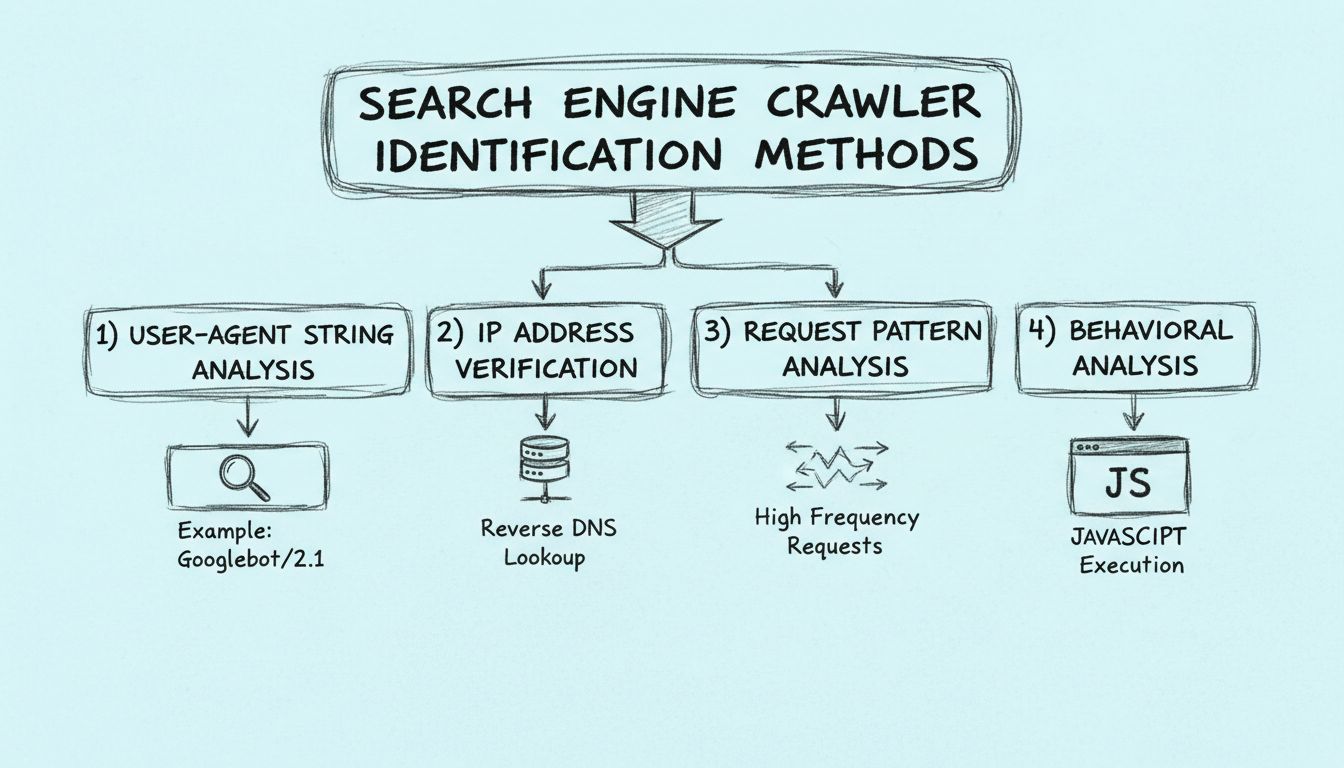
Roboty wyszukiwarek internetowych można rozpoznać na cztery główne sposoby: analizując ciąg user-agent w nagłówkach HTTP, weryfikując źródłowy adres IP i nazwę hosta z odwrotnego DNS, monitorując wzorce żądań pod kątem dużej częstotliwości oraz badając cechy zachowania, takie jak możliwość wykonywania JavaScript.
Roboty wyszukiwarek to zautomatyzowane programy, które systematycznie przeglądają internet w celu odkrywania, analizowania i indeksowania treści stron. Ich identyfikacja jest kluczowa dla webmasterów, deweloperów i marketerów afiliacyjnych, którzy muszą rozumieć wzorce ruchu na swoich stronach i zapewnić legalny dostęp robotom wyszukiwarek. W przeciwieństwie do złośliwych botów, które próbują wykradać dane lub przeprowadzać ataki, legalne roboty takie jak Googlebot, Bingbot i inne identyfikują się przez konkretne techniczne znaczniki, które można zweryfikować i potwierdzić.
Umiejętność rozróżniania legalnych robotów wyszukiwarek od innych typów botów stała się w 2025 roku szczególnie istotna, ponieważ ruch w sieci stale rośnie, a aktywność botów staje się coraz bardziej wyrafinowana. Poznanie metod identyfikacji pozwala zoptymalizować indeksowanie strony, chronić zasoby przed nieautoryzowanym dostępem oraz zapewnić, że systemy śledzenia afiliacji prawidłowo odróżniają organiczny ruch z wyszukiwarek od innych źródeł. PostAffiliatePro oferuje zaawansowane możliwości analityczne, które umożliwiają precyzyjne monitorowanie i kategoryzowanie źródeł ruchu, gwarantując, że Twój program partnerski rejestruje dokładne dane wydajności.
Najprostszą metodą identyfikacji robotów wyszukiwarek jest sprawdzenie ciągu User-Agent w nagłówku żądania HTTP. Każde żądanie HTTP zawiera nagłówek User-Agent, który identyfikuje klienta wykonującego żądanie – czy to przeglądarkę, aplikację mobilną, czy robota. Legalne roboty wyszukiwarek zawierają charakterystyczne identyfikatory w swoich ciągach User-Agent, które jasno wskazują ich pochodzenie i przeznaczenie. Na przykład robot Google identyfikuje się jako “Googlebot/2.1 (+http://www.google.com/bot.html)”, a robot Bing jako “Bingbot/2.0 (+http://www.bing.com/bingbot.htm)”.
Analizując ciągi User-Agent, należy zwracać uwagę na konkretne wzorce i słowa kluczowe wskazujące na legalne roboty wyszukiwarek. Ciąg User-Agent zazwyczaj zawiera nazwę robota, numer wersji oraz odnośnik do dokumentacji lub strony informacyjnej. Legalne roboty głównych wyszukiwarek, takich jak Google, Bing, Yahoo czy Yandex, stosują spójne konwencje nazewnicze i zawierają weryfikowalne informacje dotyczące swojego celu. Możesz rejestrować te ciągi User-Agent w logach dostępowych serwera i porównywać je z listami znanych robotów utrzymywanych przez wyszukiwarki i organizacje zajmujące się bezpieczeństwem.
| Nazwa robota | Przykładowy ciąg User-Agent | Wyszukiwarka |
|---|---|---|
| Googlebot | Googlebot/2.1 (+http://www.google.com/bot.html) | |
| Bingbot | Bingbot/2.0 (+http://www.bing.com/bingbot.htm) | Microsoft Bing |
| Slurp | Slurp/cat (+http://help.yahoo.com/help/us/ysearch/slurp) | Yahoo |
| Yandexbot | Mozilla/5.0 (compatible; YandexBot/3.0) | Yandex |
| DuckDuckBot | DuckDuckBot/1.0 (+http://duckduckgo.com/duckduckbot.html) | DuckDuckGo |
Jednak poleganie wyłącznie na ciągach User-Agent ma swoje ograniczenia. Złośliwe boty mogą podszywać się pod legalne roboty, fałszując ciąg User-Agent, dlatego ważne jest łączenie tej metody z dodatkowymi technikami weryfikacji. Ponadto niektóre legalne roboty mogą w określonych sytuacjach używać ogólnych lub zmodyfikowanych ciągów User-Agent, więc krzyżowa weryfikacja z innymi metodami daje bardziej wiarygodne rezultaty.
Skonfiguruj zaawansowane śledzenie w kilka minut. Karta kredytowa nie jest wymagana.
Drugą kluczową metodą identyfikacji robotów wyszukiwarek jest weryfikacja adresu IP źródła oraz wykonanie odwrotnego sprawdzenia DNS. Gdy robot wysyła żądanie do Twojego serwera, pochodzi ono z konkretnego adresu IP, który można zarejestrować i przeanalizować. Wyszukiwarki publikują zakresy adresów IP używanych przez swoje roboty, co pozwala webmasterom sprawdzić, czy żądanie rzeczywiście pochodzi z infrastruktury danej wyszukiwarki. Google, na przykład, prowadzi szczegółową listę adresów IP używanych przez Googlebota i inne roboty Google.
Odwrotny DNS (reverse DNS lookup) to szczególnie skuteczna technika weryfikacji, polegająca na zapytaniu systemu DNS o nazwę hosta przypisaną do adresu IP. Jeśli wykonasz odwrotny DNS na adresie IP deklarującym się jako Google, powinien on rozwiązywać się do hosta w domenie Google (np. “crawl-66-249-64-1.googlebot.com”). Następnie należy wykonać bezpośrednie sprawdzenie DNS, potwierdzając, że nazwa hosta rozwiązuje się na ten sam adres IP, tworząc dwukierunkowy łańcuch weryfikacji. Ten proces znacząco utrudnia podszywanie się pod roboty wyszukiwarek, ponieważ wymaga kontroli zarówno nad adresem IP, jak i powiązanymi rekordami DNS.
Oficjalna dokumentacja Google zaleca tę metodę jako najpewniejszy sposób potwierdzania żądań Googlebota. Proces polega na sprawdzeniu, czy odwrotny DNS hosta pasuje do wzorca domeny Google, a następnie weryfikacji, czy bezpośredni DNS tej nazwy hosta zwraca ten sam adres IP. Ta metoda jest szczególnie cenna dla stron o dużym ruchu i sieci afiliacyjnych, które muszą zapewnić dokładne przypisanie ruchu i zapobiegać zliczaniu nielegalnych botów jako ruchu z wyszukiwarek.
Analiza wzorców żądań zapewnia cenne informacje na temat zachowania robotów poprzez badanie, jak żądania są rozłożone w czasie i na zasobach Twojej strony. Legalne roboty wyszukiwarek podążają za przewidywalnymi schematami, które znacząco różnią się od ludzkiego surfowania czy działań złośliwych botów. Roboty te zwykle wykonują żądania w stałych odstępach czasu, logicznie przeszukując strukturę URL Twojej strony i respektując polecenia określone w pliku robots.txt. Monitorując te schematy, możesz rozpoznać legalne roboty i odróżnić je od podejrzanej aktywności.
Przy analizie wzorców żądań warto zwrócić uwagę na kilka kluczowych cech zachowań robotów. Po pierwsze, sprawdź częstotliwość i rozkład żądań — legalne roboty zwykle rozkładają żądania, aby nie przeciążać serwera, często wdrażając algorytmy eksponencjalnego opóźniania w przypadku błędów HTTP 500 lub innych oznak przeciążenia. Po drugie, przeanalizuj sposób przeszukiwania URL — legalne roboty systematycznie podążają za linkami i szanują strukturę witryny, podczas gdy złośliwe boty często wykonują losowe lub sekwencyjne żądania do nieistniejących bądź niepodlinkowanych adresów. Po trzecie, monitoruj typy żądanych zasobów — legalne roboty zwykle pobierają strony HTML, pliki CSS i JavaScript potrzebne do renderowania stron, unikając niepotrzebnych żądań do plików binarnych czy wrażliwych katalogów.
Możesz wdrożyć monitorowanie wzorców żądań przez analizę logów serwera i identyfikację skupisk żądań o wspólnych cechach. Narzędzia analityczne i oprogramowanie do analizy logów mogą zautomatyzować ten proces, oznaczając nietypowe schematy. Na przykład, jeśli jeden adres IP wykonuje 1000 żądań na minutę do różnych stron produktów w sekwencyjnym porządku, najprawdopodobniej jest to robot. Dla kontrastu, legalne roboty wyszukiwarek zwykle wykonują żądania znacznie rzadziej, często rozkładając je w odstępach kilku sekund, by nie obciążać serwera i unikać blokad.
Bądź pierwszym, który dowie się o nowych funkcjach i aktualizacjach produktu.
Analiza zachowań bada, jak roboty wchodzą w interakcję z treścią i technologią Twojej strony, dostarczając wskazówek pozwalających odróżnić legalne roboty wyszukiwarek od innych botów. Jedną z najważniejszych cech jest możliwość wykonywania JavaScript. Nowoczesne wyszukiwarki, takie jak Google, renderują strony przy użyciu przeglądarki bez interfejsu (headless), podobnej do Chrome, by wykonywać JavaScript i uzyskiwać dostęp do dynamicznie generowanych treści. Oznacza to, że legalne roboty wykonują kod JavaScript na Twoich stronach, podczas gdy wiele złośliwych botów nie potrafi tego zrobić lub tego nie robi.
Możesz wykrywać wykonywanie JavaScript, umieszczając kod śledzący, który działa tylko wtedy, gdy JavaScript jest aktywny i sprawny. Jeśli żądanie uzyskuje dostęp do strony, ale nie uruchamia śledzenia zależnego od JavaScript lub nie ładuje dynamicznych treści, może to oznaczać, że nie jest to nowoczesny robot wyszukiwarki. Ponadto legalne roboty zazwyczaj pobierają wszystkie zasoby niezbędne do pełnego renderowania strony, w tym obrazy, arkusze stylów i pliki JavaScript, podczas gdy proste boty mogą pobierać tylko plik HTML bez ładowania dodatkowych zasobów.
Kolejnym ważnym wskaźnikiem zachowań jest sposób obsługi elementów interaktywnych i formularzy. Legalne roboty wyszukiwarek nie wysyłają formularzy, nie klikają przycisków ani nie wchodzą w interakcję z dynamiczną zawartością w sposób, który mógłby wywołać niepożądane skutki, jak składanie zamówień czy modyfikacja danych. Skupiają się na odczycie i analizie treści, a nie na interakcji. Złośliwe boty często próbują korzystać z formularzy, przesyłać dane lub wywoływać działania mogące zaszkodzić stronie lub wykradać informacje. Monitorując tego typu zachowania, możesz wychwycić żądania próbujące nieautoryzowanych interakcji i odróżnić je od aktywności legalnych robotów.
Najskuteczniejsze podejście do rozpoznawania robotów polega na połączeniu wszystkich czterech metod w jeden kompleksowy workflow weryfikacyjny. Zamiast polegać na pojedynczej metodzie, wdrożenie warstwowego systemu weryfikacji zapewnia solidną ochronę przed podszywaniem się pod roboty i gwarantuje precyzyjne przypisywanie ruchu. Zacznij od rejestrowania ciągu User-Agent i adresu IP z każdego żądania, a następnie porównaj je z bazami znanych robotów prowadzonymi przez wyszukiwarki i organizacje bezpieczeństwa. Następnie wykonaj odwrotny DNS, by sprawdzić, czy nazwa hosta adresu IP odpowiada domenie deklarowanej wyszukiwarki. Na końcu przeanalizuj wzorce żądań i cechy zachowań, by potwierdzić zgodność aktywności z typowymi robotami wyszukiwarek.
Takie wielowarstwowe podejście jest szczególnie ważne dla sieci afiliacyjnych i platform marketingu efektywnościowego, takich jak PostAffiliatePro, gdzie prawidłowe przypisywanie ruchu ma bezpośredni wpływ na naliczanie prowizji i integralność programu. Dzięki wdrożeniu kompleksowego systemu identyfikacji robotów możesz mieć pewność, że Twoje systemy śledzenia afiliacji precyzyjnie odróżniają ruch z wyszukiwarek, ruch z reklam płatnych oraz organicznych użytkowników. Taka precyzja umożliwia lepszą analizę wyników, dokładniejsze kalkulacje ROI i skuteczniejsze wykrywanie nadużyć.
Nowoczesna infrastruktura webowa wymaga zaawansowanych systemów identyfikacji robotów, które poradzą sobie z rosnącą złożonością ruchu w sieci. Po pierwsze, utrzymuj aktualną listę legalnych adresów IP i ciągów User-Agent robotów, subskrybując oficjalne powiadomienia największych wyszukiwarek. Google, Bing i inne regularnie informują o nowych robotach lub zmianach w infrastrukturze, a śledzenie tych aktualizacji zapewnia bieżącą skuteczność systemów identyfikacyjnych. Po drugie, wdrażaj logowanie po stronie serwera, które rejestruje wszystkie istotne metadane żądań: ciągi User-Agent, adresy IP, czas żądań i żądane zasoby. Te dane stanowią podstawę do analizy wzorców i monitorowania zachowań.
Po trzecie, rozważ wdrożenie API lub usługi weryfikującej roboty, która automatycznie sprawdza tożsamość robotów w czasie rzeczywistym. Wiele platform bezpieczeństwa i analitycznych oferuje takie usługi, utrzymując aktualne bazy legalnych robotów i weryfikując żądania na ich podstawie. Po czwarte, ustal jasne zasady obsługi nierozpoznanych lub podejrzanych robotów. Możesz obsługiwać te żądania normalnie, jednocześnie je logując, lub wdrożyć limity żądań, by zapobiec nadmiernemu zużyciu zasobów. Na koniec regularnie przeglądaj i aktualizuj reguły oraz progi identyfikacji robotów na podstawie obserwowanych wzorców ruchu i nowych zagrożeń. Krajobraz robotów internetowych stale się zmienia, więc Twoje systemy identyfikacji powinny być na bieżąco dostosowywane.
Identyfikacja robotów wyszukiwarek wymaga dogłębnego zrozumienia wielu metod weryfikacji i umiejętności ich łączenia w skuteczny system wykrywania. Analizując ciągi User-Agent, weryfikując adresy IP poprzez odwrotny DNS, monitorując wzorce żądań oraz badając cechy zachowań, możesz wiarygodnie odróżnić legalne roboty wyszukiwarek od innych botów i źródeł ruchu. Ta umiejętność jest niezbędna dla webmasterów, deweloperów i marketerów afiliacyjnych, którzy muszą rozumieć źródła swojego ruchu oraz zapewnić precyzyjne śledzenie wyników. Zaawansowana analityka i monitorowanie ruchu w PostAffiliatePro pomagają skutecznie wdrażać te metody identyfikacji, gwarantując, że Twój program partnerski rejestruje dokładne dane i zachowuje integralność w coraz bardziej złożonym cyfrowym świecie.
PostAffiliatePro to wiodące oprogramowanie do zarządzania afiliacją, które pozwala precyzyjnie śledzić, zarządzać i optymalizować swoją sieć partnerską. Identyfikuj wiarygodne źródła ruchu i maksymalizuj efektywność swojego programu partnerskiego dzięki zaawansowanej analityce i monitorowaniu w czasie rzeczywistym.
Wyszukiwarka to oprogramowanie stworzone, aby ułatwić użytkownikom wyszukiwanie w internecie. Przeszukuje miliony stron i dostarcza najbardziej trafne wyniki....
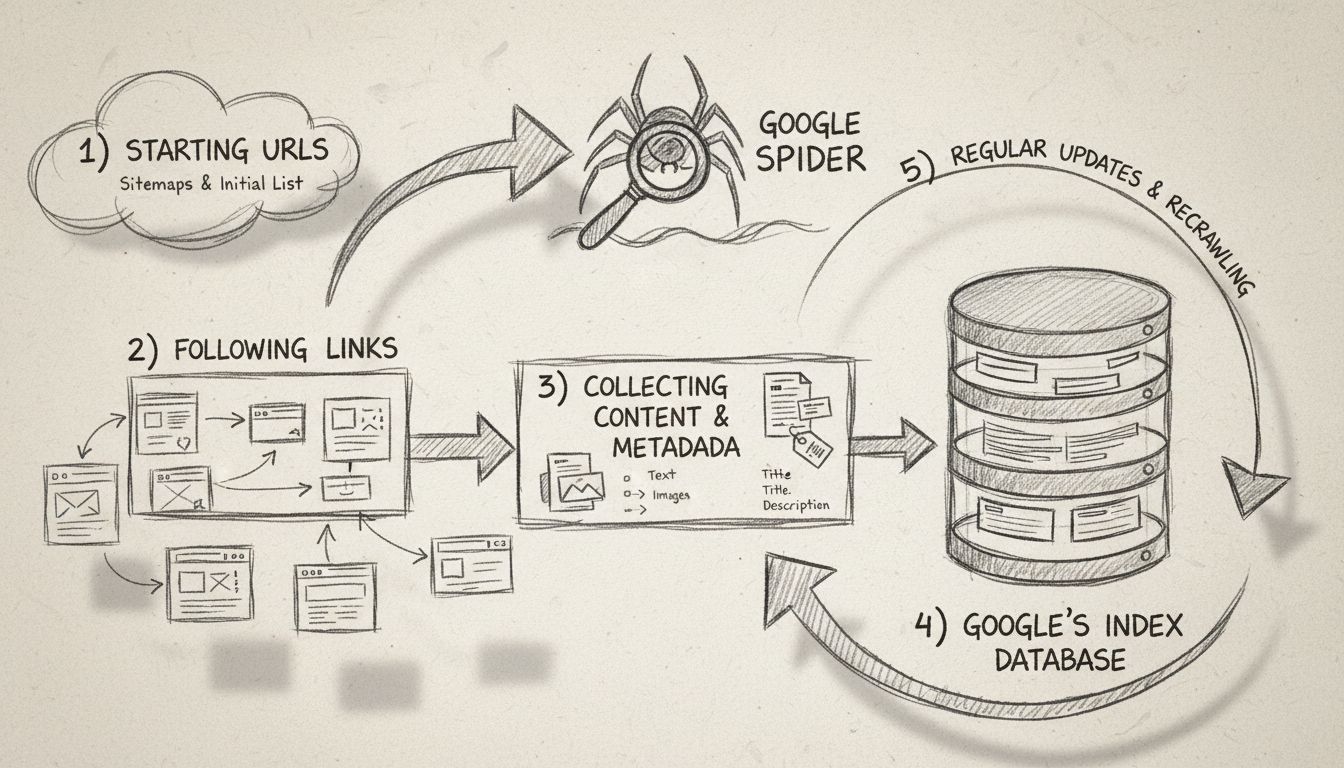
Dowiedz się, czym jest Google Spider (Googlebot), jak przeszukuje i indeksuje strony internetowe oraz dlaczego jest kluczowy dla SEO. Odkryj, jak zoptymalizować...
Crawlery gromadzą dane i informacje z internetu, odwiedzając strony i czytając ich zawartość. Dowiedz się o nich więcej.
Dołącz do naszej społeczności zadowolonych klientów i zapewnij doskonałą obsługę klienta dzięki PostAffiliatePro.
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.