
Jak naprawić problemy z duplikacją treści: Kompletny przewodnik SEO
Poznaj sprawdzone metody naprawy problemów z duplikacją treści, w tym przekierowania 301, tagi kanoniczne i dyrektywy noindex. Chroń swoje pozycje SEO dzięki ek...
11 min czytania
Dowiedz się, dlaczego zduplikowana treść szkodzi SEO, jak wpływa na pozycje w rankingach oraz poznaj sprawdzone rozwiązania, takie jak tagi kanoniczne i przekierowania 301, aby naprawić problemy ze zduplikowaną treścią w 2025 roku.
Tak, zduplikowana treść może negatywnie wpłynąć na SEO, wprowadzając wyszukiwarki w błąd co do tego, którą wersję należy wyświetlać, rozpraszając wartość linków pomiędzy wieloma adresami URL, marnując budżet indeksowania oraz potencjalnie pozwalając, by skopiowana treść zajęła wyższe pozycje od Twoich oryginalnych stron. Chociaż Google nie nakłada bezpośrednio kary za zduplikowaną treść, jej pośrednie skutki mogą znacząco zaszkodzić widoczności w wyszukiwarce i ruchowi organicznemu.
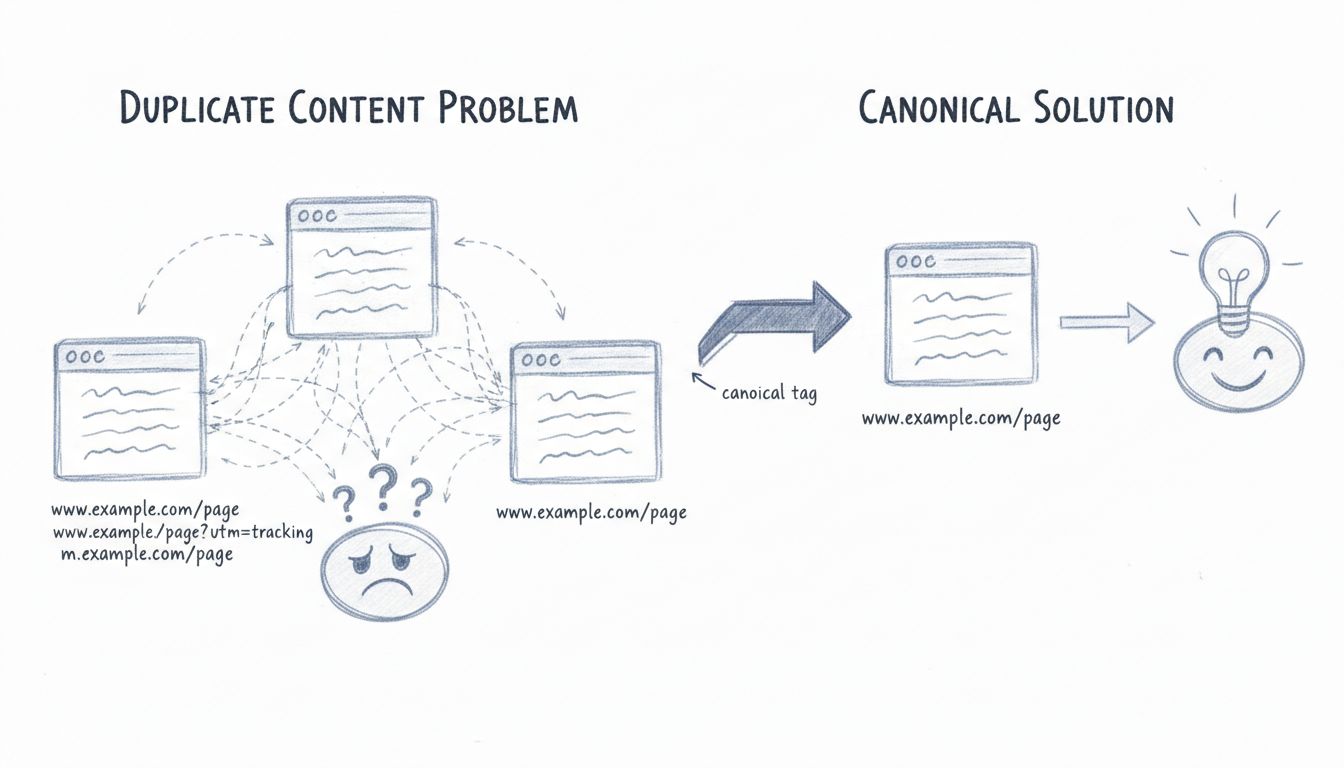
Zduplikowana treść to identyczne lub bardzo podobne teksty, które pojawiają się w internecie pod wieloma adresami URL. Może to mieć miejsce zarówno w obrębie jednej witryny, jak i na różnych domenach. Według najnowszych danych, około 25-30% sieci stanowi zduplikowana treść, co czyni ją jednym z najczęstszych technicznych wyzwań SEO, z jakimi mierzą się właściciele stron. Gdy wyszukiwarki napotykają wiele wersji tej samej treści, muszą zdecydować, która z nich jest źródłowa, którą zaindeksować i którą wyświetlać w wynikach. Ten proces decyzyjny generuje szereg komplikacji, które mogą negatywnie wpłynąć na widoczność strony w wyszukiwarkach i ruch organiczny.
Dezorientacja, jaką zduplikowana treść wprowadza w działaniu wyszukiwarek, różni się zasadniczo od bezpośredniej kary. Google wielokrotnie podkreślało, że nie nakłada kary za zduplikowaną treść. Nie oznacza to jednak, że duplikaty są nieszkodliwe. Ich pośrednie skutki mogą być równie szkodliwe dla SEO, jak bezpośrednia kara. Zrozumienie tych konsekwencji ma kluczowe znaczenie dla utrzymania zdrowej, dobrze zoptymalizowanej witryny osiągającej dobre wyniki w wyszukiwarkach.
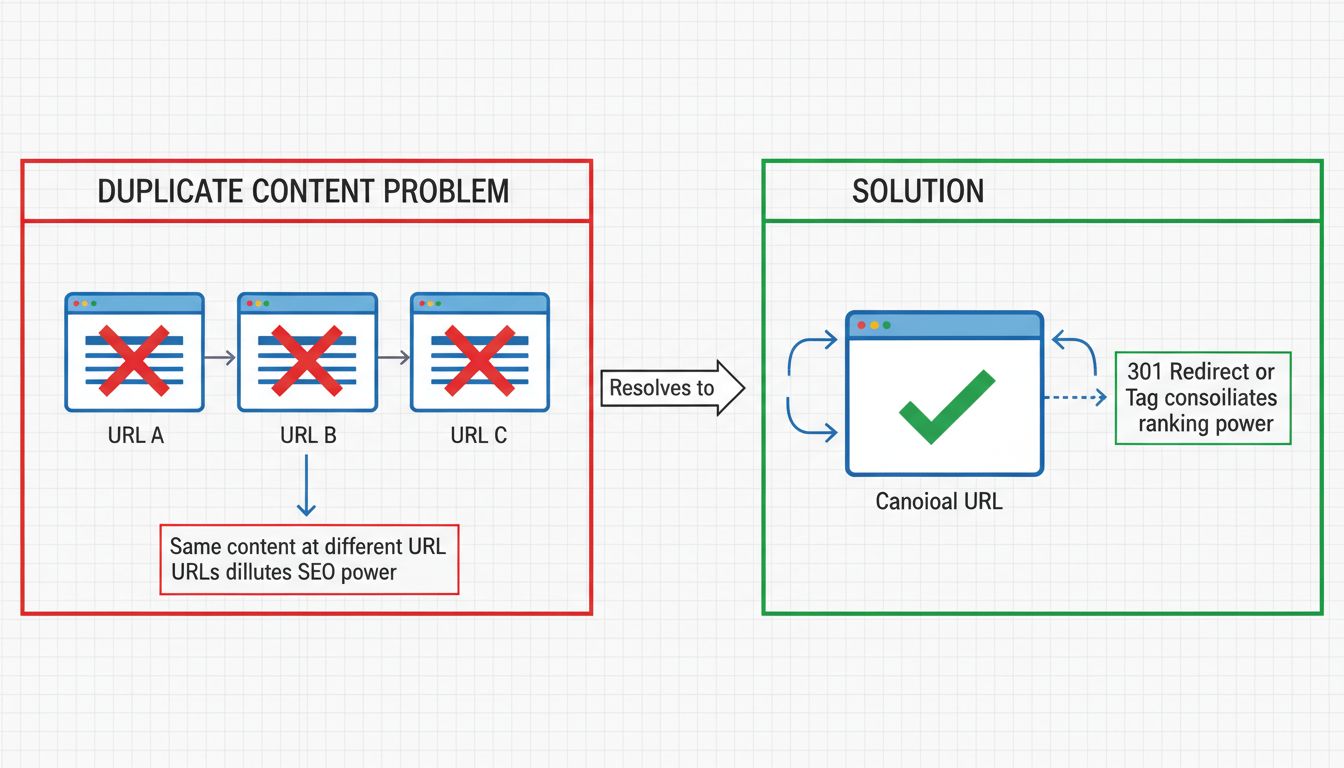
Wyszukiwarki takie jak Google stosują zaawansowane algorytmy, by określić, którą wersję zduplikowanej treści zaindeksować i wyświetlać. Gdy istnieje kilka wersji tego samego tekstu, wyszukiwarki muszą skonsolidować te strony w tzw. „klaster duplikatów”. Z tego zestawu Google wybiera adres URL, który jego zdaniem najlepiej reprezentuje treść w wynikach wyszukiwania. Ten proces, zwany kanonikalizacją, powinien skupić całą wartość linków i moc rankingową w jednym adresie URL.
Niestety, ten automatyczny proces nie zawsze działa idealnie. Zdarza się, że wyszukiwarka wybierze nieodpowiednią wersję jako kanoniczną, przez co w wynikach pojawiają się niepożądane lub nieprzyjazne użytkownikowi adresy. Na przykład, jeśli ta sama treść jest dostępna pod example.com/page/ oraz example.com/page?utm_source=newsletter, Google może wyświetlić w wynikach wersję z parametrami śledzącymi zamiast czystego adresu. Użytkownicy widząc takie nieprzyjazne linki, rzadziej w nie klikają, co prowadzi do niższego CTR i ogranicza ruch organiczny, nawet gdy Twoja strona jest wysoko w wynikach.
Skonfiguruj zaawansowane śledzenie w kilka minut. Karta kredytowa nie jest wymagana.
Jednym z najpoważniejszych skutków zduplikowanej treści jest rozproszenie wartości linków (link equity). Gdy ta sama treść jest dostępna pod wieloma adresami URL, linki z innych stron mogą prowadzić do różnych wersji tej treści. Zamiast kumulować całą wartość linków na jednej, autorytatywnej stronie, jest ona rozpraszana pomiędzy duplikaty. To osłabia sygnał autorytetu, na podstawie którego wyszukiwarki ustalają pozycje w wynikach.
Przykład z praktyki: jeśli Twoja treść jest dostępna pod buffer.com/library/social-media-manager-checklist oraz buffer.com/resources/social-media-manager-checklist, strony zewnętrzne mogą linkować do różnych adresów. Jeden adres może mieć 106 domen odsyłających, a drugi 144. Chociaż proces kanonikalizacji w Google teoretycznie powinien łączyć te linki w jeden adres, w praktyce obie wersje mogą być nadal widoczne osobno, przez co wartość linków nie jest w pełni skonsolidowana. W efekcie zamiast jednej bardzo silnej strony masz dwie o umiarkowanej sile, co ogranicza Twoje szanse na wyższe pozycje i większy ruch.
Wyszukiwarki przydzielają każdej stronie określony budżet indeksowania, czyli liczbę stron, które zostaną zaindeksowane w danym czasie. Jeśli Twoja witryna zawiera dużo zduplikowanej treści, wyszukiwarki marnują ten cenny budżet na przeszukiwanie i ponowne przeszukiwanie duplikatów, zamiast odkrywać nowe lub zaktualizowane strony. Jest to szczególnie problematyczne dla stron z wolnym serwerem lub ograniczonymi zasobami, ponieważ Google szybciej indeksuje strony bardziej responsywne.
Marnowanie budżetu indeksowania na duplikaty może prowadzić do opóźnień w indeksowaniu nowych stron oraz aktualizacji istniejących. Oznacza to, że nowa treść pojawi się w wynikach wyszukiwania z opóźnieniem, a zmiany w istniejących artykułach nie zostaną szybko odzwierciedlone w indeksie Google. Dla serwisów z dużą ilością treści lub często publikujących nowe materiały, takie opóźnienia mogą prowadzić do znacznej utraty ruchu i widoczności.
Bądź pierwszym, który dowie się o nowych funkcjach i aktualizacjach produktu.
| Przyczyna | Opis | Rozwiązanie |
|---|---|---|
| Parametry URL | Parametry śledzące (kody UTM), identyfikatory sesji, filtry tworzą wiele adresów z tą samą treścią | Stosuj tagi kanoniczne lub przekierowania 301 do czystych adresów URL |
| HTTPS vs HTTP | Treść dostępna zarówno przez wersję zabezpieczoną, jak i niezabezpieczoną | Skonfiguruj serwer, by przekierowywał cały ruch na wersję HTTPS |
| WWW vs bez WWW | Treść dostępna pod www.example.com oraz example.com | Ustaw preferowaną domenę w Google Search Console i użyj przekierowań |
| Ukośniki na końcu | Adresy z i bez ukośnika traktowane jako oddzielne strony | Wprowadź spójne przekierowania (np. zawsze z ukośnikiem na końcu) |
| Wersje mobilne | Oddzielne adresy mobilne (m.example.com) z tą samą treścią | Użyj tagów rel=“alternate” lub projektuj responsywnie |
| Strony AMP | Accelerated Mobile Pages tworzą duplikaty | Kanonikalizuj strony AMP do wersji nie-AMP |
| Wersje do druku | Wersje do druku z tą samą treścią | Kanonikalizuj wersje do druku do oryginalnych stron |
| Strony tagów/kategorii | Wiele stron tagów z tą samą treścią, gdy tylko jeden artykuł używa tych tagów | Nadaj tagom o niskiej wartości noindex lub scal tagi |
| Paginacja | Paginacja komentarzy lub produktów generuje wiele podobnych stron | Użyj rel=“prev” i rel=“next” lub nadaj paginowanym stronom noindex |
| Środowiska testowe | Strony testowe/dev indeksowane przez wyszukiwarki | Chroń testy przez robots.txt, noindex lub autoryzację |
Choć wewnętrzne problemy z duplikatami są powszechne, także zewnętrzna zduplikowana treść może zaszkodzić SEO. Gdy inne strony kopiują Twoje treści lub publikują je bez zgody, tworzą duplikaty na różnych domenach. W rzadkich przypadkach, jeśli taka strona ma wyższy autorytet domeny, Google może błędnie uznać jej wersję za oryginał i wyświetlać ją wyżej niż Twoją. Jest to szczególnie groźne dla nowych lub mniejszych serwisów rywalizujących z większymi.
Aby temu zapobiec, stosuj na wszystkich stronach tagi kanoniczne wskazujące na samą siebie. Taki tag sygnalizuje wyszukiwarkom, że to właśnie ta strona jest wersją autorytatywną. Choć nie wszyscy scraperzy zachowają Twój kod HTML, ci którzy to zrobią, zobaczą Twój tag kanoniczny i zrozumieją, że Twoja wersja jest oryginałem. Ponadto, jeśli celowo syndykujesz treści, zawsze proś inne strony o dodanie tagu kanonicznego prowadzącego do Twoich oryginałów. Dzięki temu nawet jeśli tekst pojawia się w wielu miejscach, cała wartość SEO wraca do Ciebie.
Tag kanoniczny to jedno z najskuteczniejszych i najczęściej stosowanych rozwiązań do zarządzania zduplikowaną treścią. Ten element HTML informuje wyszukiwarki, która wersja strony powinna być traktowana jako źródłowa. Tag kanoniczny umieszczony jest w sekcji <head> kodu i wygląda tak:
<link rel="canonical" href="https://www.example.com/page/" />
Dodając ten tag do duplikatów i kierując je na wersję kanoniczną (oryginalną), sprawiasz, że wyszukiwarki konsolidują moc rankingową i wartość linków w jednym adresie. Tag kanoniczny przekazuje prawie tyle samo wartości linków, co przekierowanie 301, ale jest łatwiejszy do wdrożenia, gdyż nie wymaga zmian na poziomie serwera. To szczególnie przydatne przy duplikatach wynikających z parametrów URL, wersji mobilnych czy stron AMP.
Przekierowanie 301 to trwałe przekierowanie, które informuje użytkowników i wyszukiwarki, że strona została na stałe przeniesiona w nowe miejsce. Stosując przekierowania 301 z duplikatów na wersję kanoniczną, konsolidujesz całą moc rankingową i wartość linków w jednym adresie. To często najlepsze rozwiązanie, gdy chcesz całkowicie wyeliminować duplikaty z witryny.
Przykładowo, jeśli Twoja strona jest dostępna pod http://example.com i https://www.example.com, ustaw przekierowania 301, aby cały ruch i boty były kierowane na preferowaną wersję. Dzięki temu wyszukiwarki indeksują tylko jedną wersję, eliminując problem duplikatów. Przekierowanie 301 przekazuje niemal 100% wartości linków na stronę docelową, co czyni je doskonałym wyborem do konsolidacji treści.
Meta tag robots noindex jest szczególnie przydatny do zarządzania zduplikowaną treścią, którą chcesz zostawić widoczną dla użytkowników, ale nie chcesz, by była indeksowana przez wyszukiwarki. Dodając <meta name="robots" content="noindex,follow"> do sekcji <head>, informujesz wyszukiwarki, że nie powinny indeksować tej strony, ale mogą podążać za linkami z niej wychodzącymi.
To rozwiązanie jest idealne dla paginacji, stron tagów, stron filtrów i innych automatycznie generowanych stron, które nie mają unikalnej wartości. Ważne jednak, by nie blokować tych stron w pliku robots.txt, ponieważ Google musi je odwiedzić, by odczytać dyrektywę noindex. Tag noindex jest mniej skuteczny w konsolidacji wartości linków niż tagi kanoniczne czy przekierowania 301, ale świetnie sprawdza się przy eliminacji niskowartościowych duplikatów z wyników wyszukiwania.
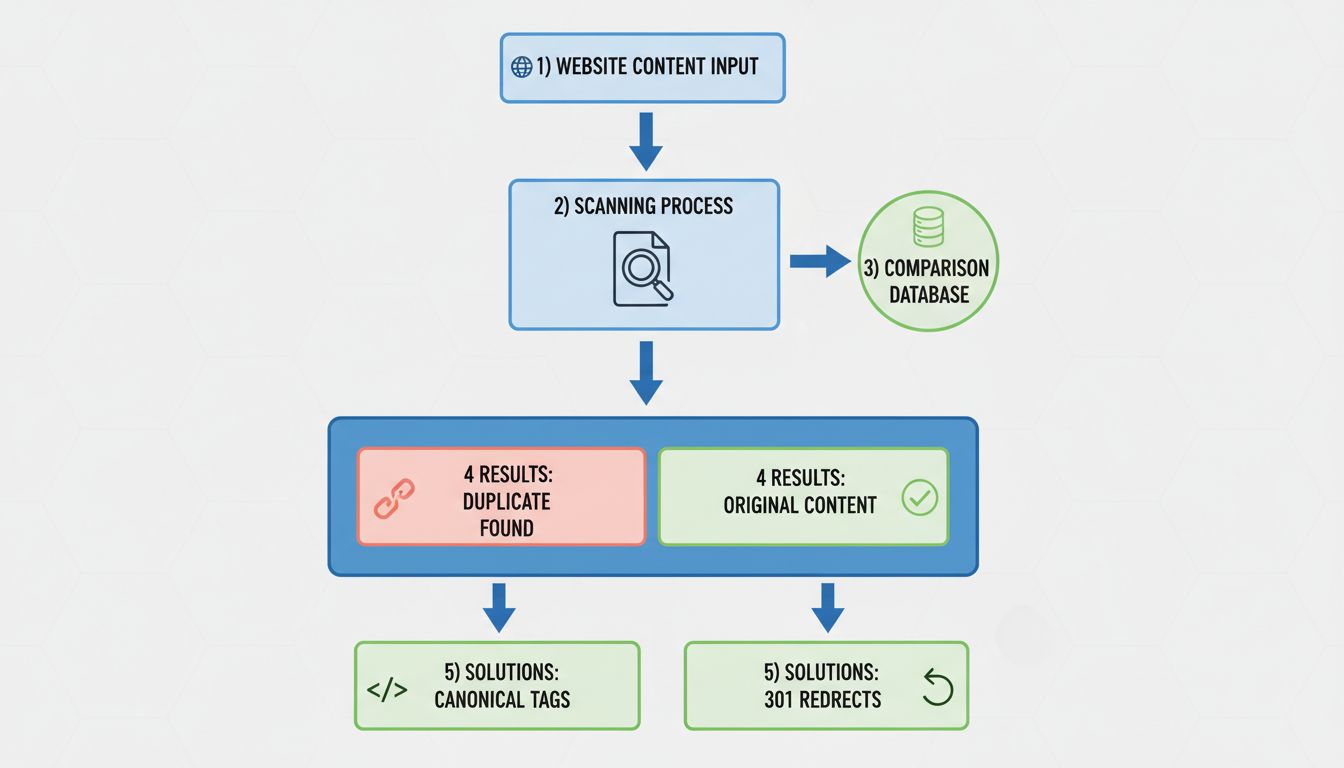
Aby wykryć problemy z duplikatami na swojej stronie, regularnie przeprowadzaj kompleksowe audyty witryny za pomocą specjalistycznych narzędzi SEO. Takie narzędzia skanują całą stronę i identyfikują podstrony o identycznej lub bardzo podobnej treści. W wynikach audytu szukaj klastrów zduplikowanych stron bez poprawnych tagów kanonicznych – to właśnie te problemy wymagają pilnej interwencji.
Google Search Console także dostarcza cennych informacji o duplikatach. Raport Stan indeksowania pokazuje, które strony Google zaindeksował oraz sygnalizuje problemy, takie jak „Duplikat bez kanonicznego wybranego przez użytkownika” lub „Duplikat, Google wybrał inną kanoniczną niż użytkownik”. Takie ostrzeżenia wskazują, że Google wykrył zduplikowaną treść i może nie obsługiwać jej zgodnie z Twoimi intencjami. Narzędzie do sprawdzania adresów URL w Search Console pozwala szczegółowo przeanalizować, jak Google traktuje dany adres – czy jest indeksowany, kanonikalizowany lub blokowany.
Zapobieganie duplikatom jest znacznie łatwiejsze niż ich późniejsze naprawianie. Zacznij od ustalenia jasnych standardów adresów URL i konsekwentnie ich przestrzegaj w całej strukturze strony. Tworząc linki wewnętrzne, zawsze kieruj do tej samej wersji adresu – nie mieszaj wersji z www i bez www, nie używaj raz ukośników, a raz nie. Ta konsekwencja pomaga wyszukiwarkom zrozumieć preferowaną strukturę linków.
Dla sklepów internetowych korzystających z nawigacji fasetowej (filtry, sortowania), wdrażaj odpowiednie zarządzanie parametrami, by nie generować setek duplikatów. Stosuj tagi kanoniczne, które kierują widoki filtrowane do podstawowej strony produktu lub korzystaj z narzędzi do obsługi parametrów w Google Search Console, by wskazać, które parametry pomijać podczas indeksowania.
Jeśli korzystasz z systemu CMS, np. WordPress, wyłącz funkcje automatycznie generujące duplikaty, takie jak osobne strony dla załączników obrazów czy paginowane komentarze. Większość nowoczesnych systemów CMS pozwala kontrolować te ustawienia. Dodatkowo, chroń środowiska testowe i deweloperskie przed indeksacją, używając robots.txt, tagów noindex lub autoryzacji HTTP, by wyszukiwarki nie indeksowały tych kopii.
Choć Google nie nakłada bezpośredniej kary za zduplikowaną treść, jej pośrednie skutki mogą poważnie zaszkodzić efektywności SEO. Duplikaty wprowadzają wyszukiwarki w błąd co do tego, którą wersję wyświetlać, rozpraszają wartość linków, marnują budżet indeksowania i mogą doprowadzić do sytuacji, w której skopiowane treści wyprzedzają Twoje oryginały. Wdrażając tagi kanoniczne, przekierowania 301 oraz dbając o prawidłową strukturę adresów, możesz zapobiec i rozwiązać problemy z duplikatami, zanim zaszkodzą widoczności Twojej strony.
Kluczem do utrzymania zdrowej strony jest proaktywne zarządzanie zduplikowaną treścią. Regularnie audytuj witrynę pod kątem duplikatów, stosuj właściwe strategie kanonikalizacji i zachowuj jednolitość adresów URL. Dzięki temu wyszukiwarki łatwo zidentyfikują Twoje treści jako autorytatywne, skonsolidują wartość linków w preferowanych adresach i efektywnie zaindeksują stronę. To przełoży się na lepsze pozycje, większy ruch organiczny i silniejsze SEO dla Twojej witryny.
Zarządzaj wieloma programami partnerskimi i zapobiegaj problemom ze zduplikowaną treścią dzięki zaawansowanym funkcjom śledzenia i zarządzania treścią w PostAffiliatePro. Zadbaj, aby Twoje działania afiliacyjne przynosiły maksymalną wartość SEO.
Poznaj sprawdzone metody naprawy problemów z duplikacją treści, w tym przekierowania 301, tagi kanoniczne i dyrektywy noindex. Chroń swoje pozycje SEO dzięki ek...
Zduplikowana treść to identyczna lub bardzo podobna zawartość pojawiająca się pod wieloma adresami URL, zarówno w obrębie jednej strony, jak i na różnych strona...
Dowiedz się, jak sprawdzić duplikaty treści za pomocą narzędzi takich jak Copyscape, Siteliner i Google Search Console. Poznaj metody ręczne, wykrywanie duplika...
Dołącz do naszej społeczności zadowolonych klientów i zapewnij doskonałą obsługę klienta dzięki PostAffiliatePro.
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.