
Crawlery i ich rola w pozycjonowaniu stron w wyszukiwarkach
Crawlery gromadzą dane i informacje z internetu, odwiedzając strony i czytając ich zawartość. Dowiedz się o nich więcej.
5 min czytania
SEO
Crawlers
+4
Dowiedz się, czym jest Google Spider (Googlebot), jak przeszukuje i indeksuje strony internetowe oraz dlaczego jest kluczowy dla SEO. Odkryj, jak zoptymalizować swoją stronę, aby poprawić indeksowanie.
Google Spider, formalnie znany jako Googlebot, to zautomatyzowany program przeszukujący strony internetowe w celu odkrywania, indeksowania i przechowywania treści w bazie danych Google. Podąża za linkami, aby odnaleźć nowe lub zaktualizowane strony, które następnie są przetwarzane i dodawane do indeksu wyszukiwarki Google, umożliwiając jej prezentowanie trafnych wyników użytkownikom.
Google Spider, bardziej formalnie znany jako Googlebot, to zautomatyzowane oprogramowanie, które systematycznie przeszukuje internet w celu odkrywania, analizowania i indeksowania treści stron internetowych. Jest to główne narzędzie Google do eksploracji stron, zbierania informacji i budowania ogromnego indeksu wyszukiwarki. Bez Googlebota Google nie byłoby w stanie odkrywać nowych stron, wykrywać zmian w istniejących treściach ani dostarczać trafnych wyników wyszukiwania miliardom użytkowników na całym świecie. Spider działa nieustannie, odwiedzając codziennie miliony stron, aby indeks Google był aktualny i kompletny.
Googlebot to w istocie zaawansowany robot indeksujący, który podąża za złożonym algorytmem decydującym, które strony odwiedzać, jak często je przeszukiwać i ile stron pobrać z każdej domeny. Crawler odczytuje kod HTML, treść tekstową oraz metadane każdej odwiedzanej strony, a następnie zapisuje te informacje w centralnej bazie danych Google. Proces indeksowania jest podstawą działania wyszukiwarek i ma bezpośredni wpływ na widoczność Twojej strony w wynikach wyszukiwania.
Google Spider działa według jasno określonego procesu przeszukiwania, który rozpoczyna się od listy początkowej znanych stron internetowych. Ta początkowa lista pochodzi z wcześniejszych przeszukiwań i jest stale uzupełniana o dane z map witryn przekazywane przez właścicieli stron w Google Search Console. Gdy Googlebot odwiedza stronę, nie tylko odczytuje jej zawartość — przeprowadza również szczegółową analizę struktury strony, podąża za linkami wewnętrznymi i zewnętrznymi oraz identyfikuje wszelkie zmiany lub nowe treści, które mogły pojawić się od ostatniej wizyty.
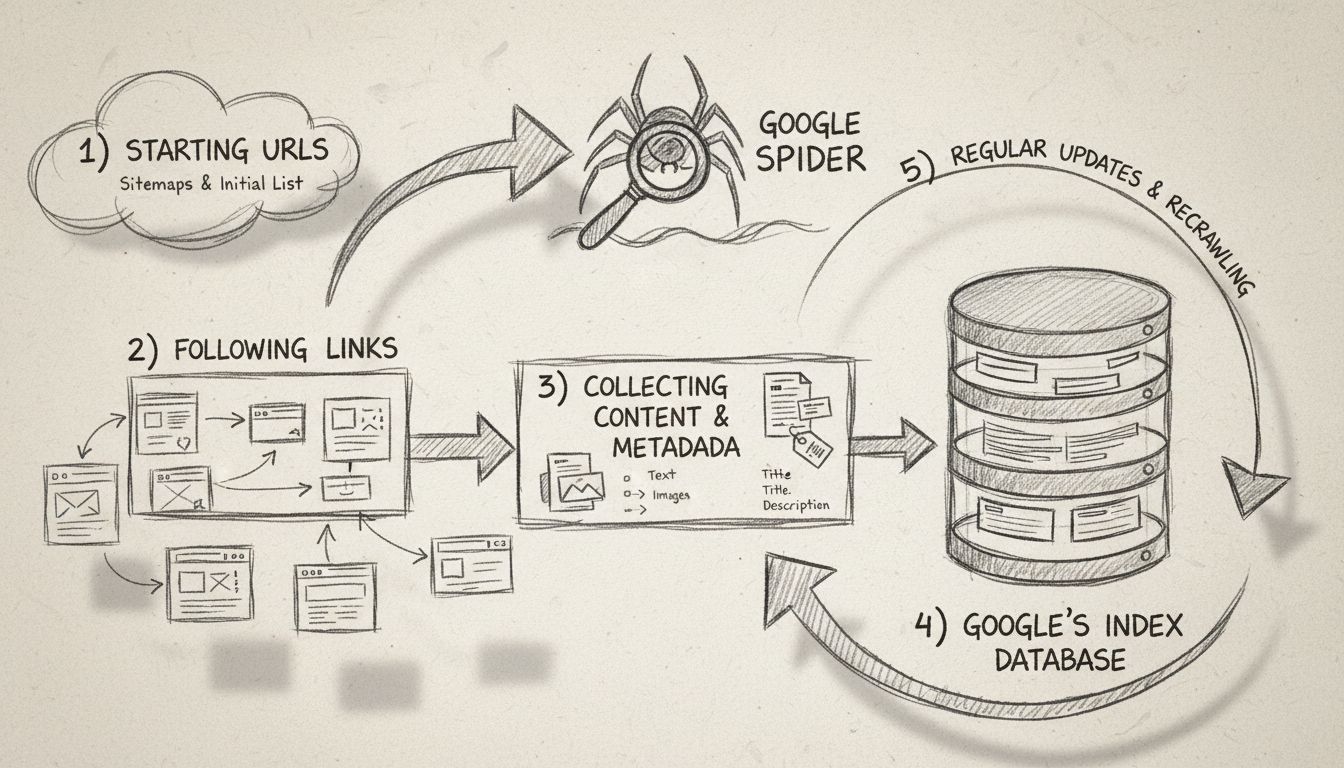
Proces przeszukiwania obejmuje kluczowe etapy: Po pierwsze, Googlebot zaczyna od listy adresów URL zgromadzonych podczas wcześniejszych przeszukiwań oraz z map witryn. Po drugie, nawigując po stronach, podąża za linkami (zarówno atrybutami SRC, jak i HREF), aby odkrywać nowe treści. Po trzecie, crawler pobiera i analizuje zawartość każdej strony, w tym tekst, strukturę HTML, metadane i inne istotne informacje. Po czwarte, zebrane dane są przesyłane na serwery Google do przetwarzania i przechowywania w indeksie wyszukiwarki. Na końcu Googlebot regularnie wraca na strony, aby sprawdzać nowe treści, aktualizacje lub zmiany w istniejących stronach.
Skonfiguruj zaawansowane śledzenie w kilka minut. Karta kredytowa nie jest wymagana.
Google obsługuje wiele wyspecjalizowanych wariantów crawlerów, z których każdy został zaprojektowany do określonych celów i identyfikowany przez unikalny ciąg user-agent. Zrozumienie tych typów pomaga właścicielom stron zoptymalizować serwisy pod odpowiedniego robota. Do głównych wariantów Googlebota należą crawler dla komputerów stacjonarnych, crawler mobilny, crawler wideo, crawler obrazów i crawler newsów — każdy z nich spełnia odrębne funkcje w ekosystemie indeksowania Google.
| Typ Googlebota | Ciąg User-Agent | Cel |
|---|---|---|
| Googlebot (Desktop) | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) | Przeszukuje wersje stron dla komputerów stacjonarnych na potrzeby ogólnego indeksu wyszukiwania |
| Googlebot (Mobile) | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) | Przeszukuje mobilne wersje stron internetowych |
| Googlebot-Video | Googlebot-Video/1.0 | Indeksuje treści wideo osadzone na stronach |
| Googlebot-Image | Googlebot-Image/1.0 | Przeszukuje i indeksuje obrazy na potrzeby wyszukiwarki Google Grafika |
| Googlebot-News | Googlebot-News | Przeszukuje treści newsowe do agregatora Google News |
Poza tymi głównymi crawlerami, Google obsługuje też specjalistyczne boty do innych celów. AdSense Bot sprawdza jakość i zgodność reklam, a crawler Mobile Apps Android indeksuje treści z aplikacji na Androida. Każdy bot posiada unikalny identyfikator user-agent, dzięki czemu administratorzy stron mogą śledzić, który konkretny crawler odwiedza ich witrynę w logach serwera. Ma to znaczenie, ponieważ różne crawlery mogą mieć różne limity przeszukiwania i priorytety, co wpływa na częstotliwość odwiedzin Twojej strony.
Google Spider ma kluczowe znaczenie dla pozycjonowania, ponieważ decyduje o tym, czy treści Twojej strony zostaną odkryte, zindeksowane i ocenione w wynikach wyszukiwania. Jeśli Googlebot nie może skutecznie przeszukiwać Twojej witryny, strony nie pojawią się w indeksie Google, przez co będą niewidoczne dla potencjalnych klientów szukających Twoich produktów lub usług. Dlatego techniczne SEO — zapewnienie przyjazności strony dla robotów — to jeden z najważniejszych fundamentów skutecznej strategii SEO.
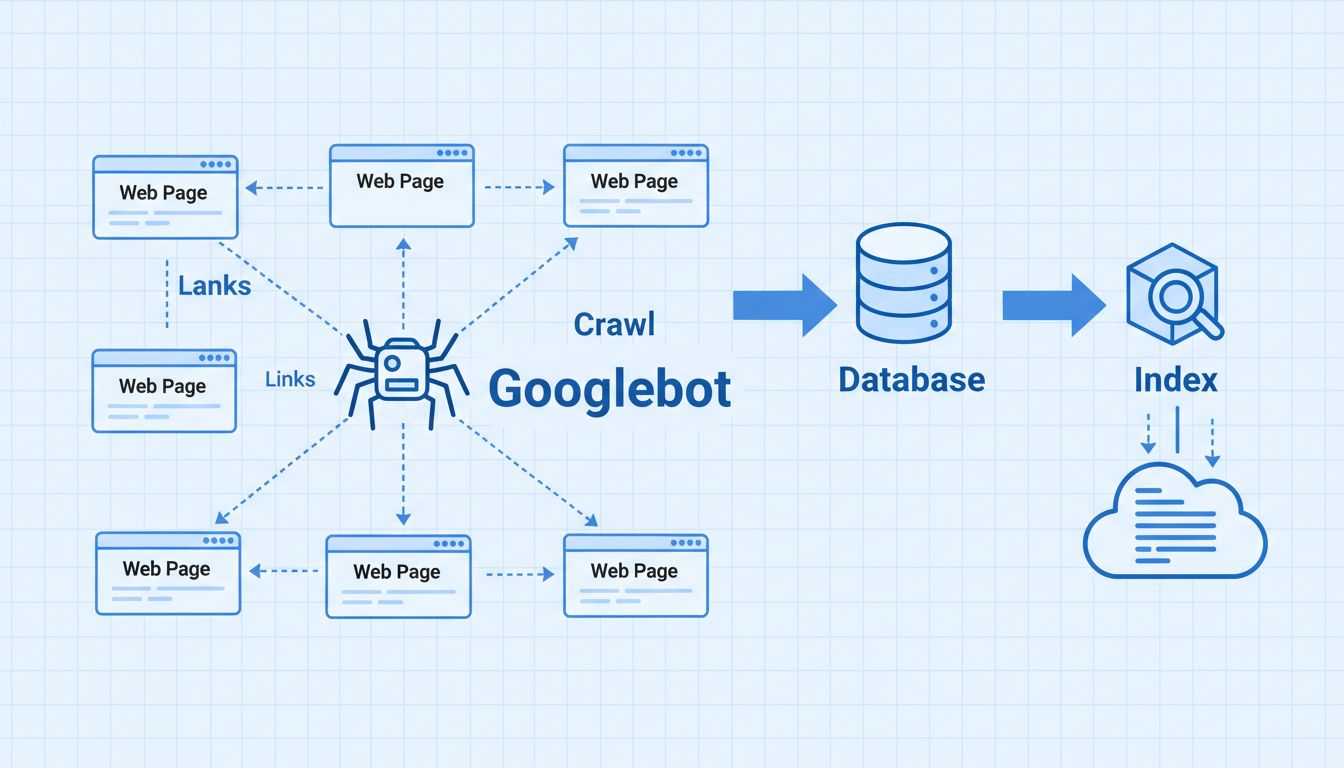
Podczas gdy Googlebot przeszukuje Twoją stronę, tworzy ogromny indeks wszystkich słów oraz ich lokalizacji na każdej stronie, a także informacji HTML, takich jak tagi tytułu, meta opisy i struktura nagłówków. Zindeksowane dane są przechowywane w bazie Google i wykorzystywane przez algorytmy do oceny stron oraz określania wartości Twoich treści dla konkretnych zapytań. Im skuteczniej Googlebot przeszukuje Twoją stronę, tym częściej wraca i szybciej indeksuje nowe treści, co zwiększa szanse na ich szybkie pojawienie się w wynikach wyszukiwania.
Bądź pierwszym, który dowie się o nowych funkcjach i aktualizacjach produktu.
Aby Googlebot mógł skutecznie i efektywnie przeszukiwać Twoją witrynę, należy wdrożyć kilka technicznych najlepszych praktyk. Po pierwsze, utrzymuj przejrzystą i logiczną strukturę strony z odpowiednią nawigacją, która ułatwia crawlerowi dostęp do wszystkich ważnych podstron. Linkowanie wewnętrzne powinno być strategiczne i powiązane tematycznie, z opisowymi tekstami kotwiczącymi, co ułatwia zarówno użytkownikom, jak i robotom zrozumienie kontekstu linkowanych stron. Twoja strona powinna ładować się szybko, ponieważ czas wczytywania wpływa na efektywność przeszukiwania i na to, jak dużą część witryny Googlebot odwiedzi w ramach przydzielonego budżetu indeksowania.
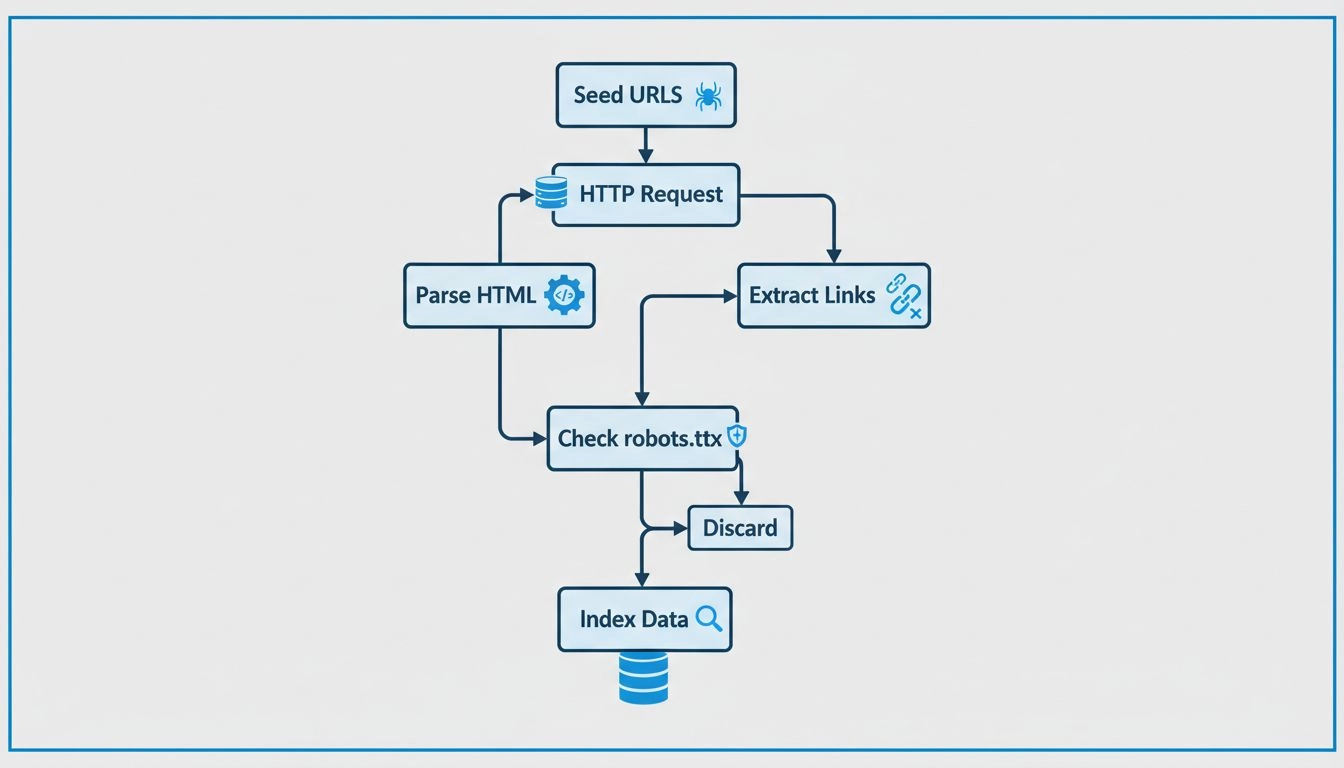
Stwórz i prześlij mapę strony w formacie XML w Google Search Console, co zapewni Googlebotowi kompleksową listę wszystkich stron przeznaczonych do indeksowania. Jest to szczególnie ważne w przypadku dużych serwisów lub stron, których nie da się łatwo odkryć wyłącznie przez linkowanie wewnętrzne. Dodatkowo upewnij się, że plik robots.txt został poprawnie skonfigurowany — zezwalaj Googlebotowi na dostęp do stron, które mają być zindeksowane, a blokuj dostęp do obszarów wrażliwych lub duplikatów treści. Uważaj jednak, aby nie zablokować przypadkowo ważnych stron, ponieważ uniemożliwi im to indeksowanie.
Google Search Console to niezbędne narzędzie do monitorowania interakcji Googlebota z Twoją stroną i wykrywania ewentualnych problemów z indeksowaniem. Sekcja Statystyki indeksowania dostarcza szczegółowych danych na temat liczby stron przeszukanych przez Googlebota, czasu spędzonego na przeszukiwaniu oraz liczby napotkanych błędów. Możesz sprawdzić średni czas odpowiedzi serwera, który bezpośrednio wpływa na efektywność przeszukiwania — wolniejszy serwer oznacza mniej stron odwiedzonych w tym samym czasie.
Raport Stan w Google Search Console pokazuje, które strony zostały zindeksowane, które zawierają błędy uniemożliwiające indeksację oraz które są wykluczone z indeksu. Te informacje są nieocenione przy wykrywaniu problemów technicznych, takich jak niedziałające linki, błędy serwera czy strony zablokowane przez robots.txt, których nie chciałeś blokować. Możesz również skorzystać z narzędzia Inspekcja adresu URL, aby sprawdzić, jak Googlebot widzi daną stronę — w tym, czy może renderować treści generowane przez JavaScript i uzyskać dostęp do wszystkich zasobów potrzebnych do prawidłowego wyświetlenia strony.
Każda strona ma tzw. “budżet indeksowania” — liczbę stron, które Googlebot odwiedzi w określonym czasie. Dla większości serwisów budżet ten nie stanowi problemu, ale w przypadku bardzo dużych stron liczących tysiące lub miliony podstron jego optymalizacja nabiera znaczenia. Google przyznaje budżet indeksowania na podstawie dwóch czynników: pojemności indeksowania (ile Twój serwer jest w stanie obsłużyć) oraz zapotrzebowania na indeksowanie (na ile Google uznaje Twoją stronę za ważną). Poprawa szybkości witryny i naprawa błędów zwiększa pojemność indeksowania, a tworzenie wartościowych, regularnie aktualizowanych treści podnosi zapotrzebowanie na indeksowanie.
Aby zoptymalizować budżet indeksowania, usuń powielone treści, które marnują zasoby crawl, napraw niesprawne linki i łańcuchy przekierowań oraz usuń strony nieprzynoszące wartości użytkownikom. Unikaj blokowania ważnych podstron przez robots.txt lub tagi noindex i zadbaj o to, by struktura serwisu umożliwiała Googlebotowi dotarcie do istotnych stron w kilku kliknięciach od strony głównej. Regularnie aktualizuj mapę strony XML i usuwaj nieaktualne podstrony, aby Googlebot skupił swoje działania na najważniejszych treściach dla Twojego biznesu.
Właściciele stron często napotykają różne problemy utrudniające skuteczne przeszukiwanie przez Googlebota. Błędy serwera (kody stanu 5xx) sygnalizują, że serwer ma problem z obsługą żądań, co może uniemożliwić indeksowanie stron. Łańcuchy przekierowań — gdy jedna strona przekierowuje do drugiej, a ta z kolei do kolejnej — marnują budżet indeksowania i spowalniają proces umieszczania treści w indeksie. Zablokowane zasoby, takie jak pliki CSS czy JavaScript zablokowane przez robots.txt, mogą uniemożliwić Googlebotowi prawidłowe renderowanie i zrozumienie strony.
Błędy typu soft 404 pojawiają się, gdy strona zwraca kod 200 (sukces), ale zawiera mało lub wcale nie zawiera treści, przez co Googlebot nie wie, czy powinna być indeksowana. Przypadkowo zastosowane tagi noindex dla ważnych podstron powodują ich wykluczenie z wyników wyszukiwania. Wolne ładowanie stron zmniejsza liczbę podstron, które Googlebot może odwiedzić w ramach przydzielonego budżetu. Aby zapobiegać tym problemom, regularnie audytuj swoją stronę za pomocą Google Search Console, monitoruj logi serwera pod kątem błędów i korzystaj z narzędzi typu Screaming Frog, by identyfikować problemy techniczne zanim wpłyną na widoczność strony.
W roku 2025 Google Spider pozostaje równie ważny jak dawniej, choć jego rola ewoluowała wraz z nowymi technologiami i formatami treści. Googlebot obecnie obsługuje renderowanie JavaScriptu, co oznacza, że potrafi indeksować treści generowane dynamicznie przez frameworki JS. Przetwarza również znaczniki danych strukturalnych (Schema.org), by lepiej rozumieć zawartość stron i wyświetlać rozbudowane fragmenty w wynikach wyszukiwania. Indeksowanie mobilne na pierwszym miejscu sprawia, że Googlebot priorytetowo przeszukuje i indeksuje wersję mobilną Twojej witryny, co czyni optymalizację mobilną niezbędną dla sukcesu SEO.
Spider odgrywa także kluczową rolę w wykrywaniu i zwalczaniu spamu, identyfikacji zainfekowanych treści oraz zapewnianiu, że wyniki wyszukiwania pozostają trafne i wiarygodne. Wraz z rozwojem wyszukiwarek i wdrażaniem technologii AI oraz uczenia maszynowego, możliwości przeszukiwania i indeksowania przez Googlebota stają się coraz bardziej zaawansowane, pozwalając Google lepiej rozumieć intencje użytkowników i dostarczać dokładniejsze wyniki. Zrozumienie działania Googlebota i odpowiednia optymalizacja strony pozostaje jednym z najważniejszych elementów skutecznej strategii SEO.
Podobnie jak Google Spider przeszukuje i indeksuje Twoje treści, PostAffiliatePro pomaga śledzić i optymalizować wyniki marketingu afiliacyjnego. Monitoruj każdy klik, konwersję i prowizję dzięki naszej wiodącej platformie do zarządzania afiliacją.
Crawlery gromadzą dane i informacje z internetu, odwiedzając strony i czytając ich zawartość. Dowiedz się o nich więcej.
Wyszukiwarka to oprogramowanie stworzone, aby ułatwić użytkownikom wyszukiwanie w internecie. Przeszukuje miliony stron i dostarcza najbardziej trafne wyniki....
Dowiedz się, jak działają web crawlery – od adresów początkowych po indeksowanie. Poznaj techniczny proces, typy crawlerów, zasady robots.txt oraz wpływ crawler...
Dołącz do naszej społeczności zadowolonych klientów i zapewnij doskonałą obsługę klienta dzięki PostAffiliatePro.
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.