
Crawlery i ich rola w pozycjonowaniu stron w wyszukiwarkach
Crawlery gromadzą dane i informacje z internetu, odwiedzając strony i czytając ich zawartość. Dowiedz się o nich więcej.
5 min czytania
SEO
Crawlers
+4
Dowiedz się, jak działają web crawlery – od adresów początkowych po indeksowanie. Poznaj techniczny proces, typy crawlerów, zasady robots.txt oraz wpływ crawlerów na SEO i marketing afiliacyjny.
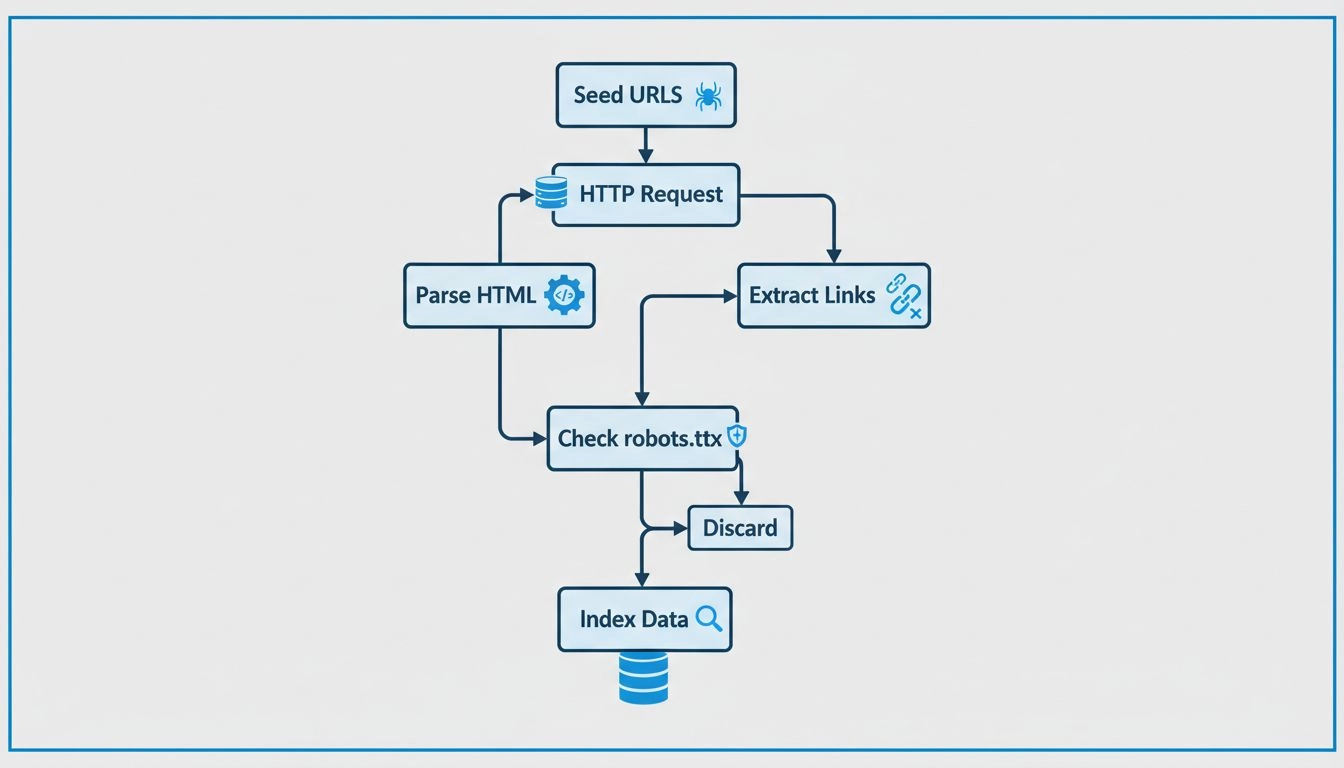
Web crawlery działają poprzez wysyłanie żądań HTTP do stron internetowych, zaczynając od adresów początkowych (seed URLs), podążając za hiperłączami w celu odkrywania nowych stron, analizując treść HTML w celu wydobycia informacji, respektując zasady robots.txt i przechowując zebrane dane w przeszukiwalnych indeksach. Systematycznie odwiedzają strony, wydobywają metadane i linki oraz powtarzają proces, by na bieżąco aktualizować bazy wyszukiwarek.
Web crawlery, znane również jako pająki lub boty, to zautomatyzowane programy, które systematycznie przeglądają internet w celu odkrywania, pobierania i analizowania treści stron internetowych. Te inteligentne agenty są podstawą infrastruktury wyszukiwarek, umożliwiając platformom takim jak Google, Bing i innym usługom wyszukiwania budowanie obszernych indeksów miliardów stron. Głównym celem web crawlerów jest zbieranie i organizowanie informacji ze stron, aby wyszukiwarki mogły szybko dostarczać trafne wyniki, gdy użytkownicy wykonują wyszukiwania. Bez web crawlerów wyszukiwarki nie miałyby możliwości odkrywania nowych treści ani bieżącego aktualizowania swoich indeksów o najnowsze informacje dostępne online.
Znaczenie web crawlerów wykracza daleko poza samą funkcję wyszukiwania. Stanowią one fundament wielu cyfrowych rozwiązań, takich jak porównywarki cen, agregatory treści, platformy badań rynkowych, narzędzia do analizy SEO czy serwisy archiwizujące treści internetowe. Dla marketerów afiliacyjnych i operatorów sieci – takich jak użytkownicy PostAffiliatePro – zrozumienie działania crawlerów jest kluczowe, aby treści afiliacyjne, strony produktowe oraz materiały promocyjne były poprawnie odkrywane i indeksowane przez wyszukiwarki. Ta widoczność bezpośrednio wpływa na ruch organiczny, generowanie leadów i w efekcie – możliwości prowizyjne.
Web crawlery podążają metodycznym i uporządkowanym procesem, aby systematycznie eksplorować internet. Proces rozpoczyna się od adresów początkowych (seed URLs), czyli znanych punktów startowych, takich jak adresy głównych stron, mapy witryn XML lub wcześniej przeszukane strony. Te adresy stanowią punkt wejścia w podróż crawlery po sieci. Crawler utrzymuje kolejkę adresów do odwiedzenia, często nazywaną „crawl frontier”, która stale się powiększa w miarę odkrywania nowych linków podczas procesu indeksowania.
Kiedy crawler dociera do danego adresu, wysyła żądanie HTTP do serwera, na którym znajduje się strona. Serwer odpowiada, przesyłając treść HTML strony, podobnie jak dzieje się to w przeglądarce, gdy odwiedzasz stronę. Następnie crawler analizuje kod HTML, aby wydobyć cenne informacje, w tym tekst, metatagi (takie jak tytuł i opis), obrazy, filmy, a co najważniejsze – hiperłącza do innych stron. Ekstrakcja linków jest kluczowa, ponieważ pozwala crawlerowi odkrywać nowe adresy, które nie zostały jeszcze odwiedzone, a które następnie trafiają do kolejki na przyszłość.
| Etap procesu crawlery | Opis | Kluczowe działania |
|---|---|---|
| Inicjalizacja | Rozpoczęcie procesu crawlowania | Załaduj seed URLs, zainicjuj kolejkę crawl |
| Żądanie i pobieranie | Pobieranie treści strony | Wyślij żądania HTTP, odbierz odpowiedzi HTML |
| Analiza HTML | Parsowanie struktury strony | Wydobądź tekst, metadane, linki, multimedia |
| Ekstrakcja linków | Wyszukiwanie nowych adresów | Zidentyfikuj hiperłącza, dodaj do kolejki |
| Sprawdzenie robots.txt | Respektowanie zasad strony | Zweryfikuj uprawnienia do crawlowania |
| Przechowywanie treści | Zapisywanie informacji | Zaindeksuj dane w przeszukiwalnej bazie |
| Priorytetyzacja | Wybór kolejnych stron | Oceń ważność i trafność adresów |
| Powtarzanie | Kontynuacja cyklu | Przetwarzaj kolejny adres z kolejki |
Zanim crawler odwiedzi nowy adres na danej domenie, odpowiedzialne boty sprawdzają plik robots.txt znajdujący się w katalogu głównym domeny. Plik ten zawiera instrukcje, za pomocą których właściciele stron komunikują się z crawlerami, wskazując, które strony mogą być indeksowane, a które powinny zostać pominięte. Przykładowo, właściciel może użyć robots.txt, by zablokować dostęp do poufnych stron, powielonej treści lub sekcji obciążających serwer. Większość legalnych crawlerów wyszukiwarek respektuje te instrukcje, by utrzymywać dobre relacje z właścicielami stron i nie powodować problemów wydajnościowych.
Skonfiguruj zaawansowane śledzenie w kilka minut. Karta kredytowa nie jest wymagana.
Nowoczesne web crawlery znacząco się rozwinęły, by sprostać złożoności współczesnych stron. Wiele witryn korzysta obecnie z JavaScriptu do dynamicznego generowania treści po załadowaniu strony, co oznacza, że początkowa odpowiedź HTML nie zawiera wszystkich danych. Zaawansowane crawlery wykorzystują dziś przeglądarki bez interfejsu (headless browsers), by renderować JavaScript i wychwycić dynamicznie ładowaną treść, która byłaby niewidoczna dla tradycyjnych crawlerów. Ta funkcja jest niezbędna do indeksowania aplikacji jednostronicowych, interaktywnych paneli czy nowoczesnych webaplikacji opartych o renderowanie po stronie klienta.
Crawlery wdrażają zaawansowane algorytmy priorytetyzacji, by efektywnie zarządzać budżetem indeksowania – ograniczoną liczbą stron, które mogą odwiedzić w danym czasie. Algorytmy te biorą pod uwagę wiele czynników, w tym autorytet strony (określany przez jakość i liczbę backlinków), strukturę linkowania wewnętrznego, świeżość treści, wolumen ruchu i reputację domeny. Strony o wysokim autorytecie i częstych aktualizacjach są odwiedzane częściej, podczas gdy mniej istotne czy statyczne strony mogą być pomijane lub indeksowane rzadziej. Inteligentna priorytetyzacja zapewnia, że crawlery koncentrują swoje zasoby na najwartościowszych i najczęściej zmieniających się treściach.
Opóźnienia crawlowania i ograniczanie szybkości (rate limiting) to ważne mechanizmy chroniące serwery przed przeciążeniem przez boty. Odpowiedzialne crawlery wprowadzają przerwy między żądaniami i respektują dyrektywy crawl-delay z plików robots.txt. Takie uprzejme zachowanie chroni wydajność stron i doświadczenie użytkownika, zapobiegając nadmiernemu zużyciu zasobów serwera przez boty. Wolno działające strony lub te generujące błędy mogą być odwiedzane rzadziej, gdy crawler automatycznie spowalnia, aby nie sprawiać problemów.
Różne typy web crawlerów pełnią odmienne funkcje w cyfrowym ekosystemie. Ogólne crawlery są wdrażane przez największe wyszukiwarki do indeksowania całego internetu, tworząc rozległe indeksy zasilające wyniki wyszukiwania. Te boty są zaprojektowane z myślą o maksymalnym zasięgu i działają nieprzerwanie, by odkrywać nowe treści i aktualizować istniejące indeksy. Pionowe lub wyspecjalizowane crawlery skupiają się na określonych branżach lub typach treści, np. crawlery ofert pracy przeszukujące portale rekrutacyjne, crawlery cen zbierające dane z e-commerce czy crawlery naukowe indeksujące publikacje naukowe.
Crawlery przyrostowe specjalizują się w efektywności, koncentrując się wyłącznie na nowych lub niedawno zmodyfikowanych treściach, zamiast wielokrotnie przeszukiwać całą witrynę. Takie podejście znacząco ogranicza obciążenie serwerów i zużycie transferu, a jednocześnie pozwala utrzymywać indeksy w miarę aktualne. Crawlery tematyczne (focused) stosują zaawansowane algorytmy, by wyszukiwać treść na określone tematy czy słowa kluczowe, inteligentnie priorytetyzując strony zawierające prawdopodobnie istotne informacje. Crawlery czasu rzeczywistego nieustannie monitorują strony i aktualizują zebrane dane w czasie rzeczywistym lub z minimalnym opóźnieniem, co czyni je idealnymi do agregacji newsów i monitorowania social mediów.
Crawlery równoległe oraz crawlery rozproszone to najbardziej zaawansowane infrastrukturalnie rozwiązania. Crawlery równoległe działają na wielu maszynach lub wątkach jednocześnie, dramatycznie zwiększając szybkość i przepustowość indeksowania. Crawlery rozproszone dzielą zadania między wiele serwerów lub centrów danych, dzięki czemu mogą efektywnie przetwarzać ogromne ilości danych. Duże wyszukiwarki, takie jak Google, używają rozproszonych architektur crawlerów do obsługi miliardów stron w sieci.
Bądź pierwszym, który dowie się o nowych funkcjach i aktualizacjach produktu.
Web crawlery odgrywają kluczową rolę w SEO, ponieważ to one decydują, które strony zostaną zaindeksowane i jak wyszukiwarka zinterpretuje Twoje treści. Jeśli crawler nie ma dostępu do danej strony, nie pojawi się ona w wynikach wyszukiwania, niezależnie od jakości czy trafności. Typowe problemy z crawlowaniem, które uniemożliwiają prawidłowe indeksowanie to: strony zablokowane przez robots.txt, uszkodzone linki wewnętrzne prowadzące do błędów 404, wolne ładowanie strony powodujące timeouty crawlerów, czy problemy z renderowaniem JavaScript, przez co boty nie widzą dynamicznie generowanych treści.
Właściciele stron mogą zoptymalizować dostęp crawlerów stosując kilka kluczowych strategii. Przejrzysta architektura strony z logiczną hierarchią nawigacji pomaga crawlerom zrozumieć powiązania i ważność podstron. Linkowanie wewnętrzne sygnalizuje botom, które strony są najważniejsze i umożliwia efektywne rozdzielanie budżetu indeksowania w obrębie witryny. Mapy witryny XML jasno wskazują wszystkie istotne strony, dzięki czemu crawlery nie pominą treści nawet na dużych lub złożonych serwisach. Szybkie ładowanie stron zachęca boty do odwiedzania większej liczby adresów w ramach przydzielonego budżetu, a świeże, regularnie aktualizowane treści sygnalizują, że strona zasługuje na częstsze odwiedziny crawlerów.
Dla marketerów afiliacyjnych korzystających z PostAffiliatePro zapewnienie odpowiedniego dostępu crawlerów jest kluczowe dla generowania ruchu organicznego do treści afiliacyjnych. Gdy Twoje strony produktowe, artykuły porównawcze i materiały promocyjne są poprawnie crawlowane i indeksowane, mają szansę pojawić się w wynikach wyszukiwania i przyciągać wartościowy ruch. Problemy z crawlowaniem mogą skutkować utraconymi możliwościami indeksowania i mniejszą widocznością Twoich ofert afiliacyjnych.
Właściciele stron mają do dyspozycji kilka mechanizmów kontroli nad zachowaniem crawlerów na swoich witrynach. Podstawowym narzędziem jest plik robots.txt, zawierający dyrektywy określające, które typy botów (user-agents) mają dostęp do poszczególnych części serwisu. Dobrze skonfigurowany robots.txt pozwala oszczędzić zasoby, blokując crawlowanie powielonych treści, środowisk testowych czy stron obciążających serwer, jednocześnie umożliwiając swobodny dostęp do kluczowych treści. Meta tag robots umieszczany w kodzie HTML poszczególnych stron daje kontrolę na poziomie podstrony, pozwalając wykluczyć ją z indeksowania lub zignorować jej linki.
Atrybut nofollow w linkach informuje boty, by nie podążały za danym hiperłączem – przydatne, gdy chcemy uniknąć crawlowania linków do nieznanych zaufania stron zewnętrznych lub treści generowanych przez użytkowników. Te mechanizmy kontroli pozwalają właścicielom stron precyzyjnie sterować zachowaniem crawlerów i utrzymywać dobre relacje z wyszukiwarkami. Należy jednak pamiętać, że złośliwe boty i agresywne crawlery często ignorują te dyrektywy, dlatego czasem konieczne są dodatkowe zabezpieczenia, takie jak ograniczanie szybkości czy systemy wykrywania botów.
Dla operatorów sieci afiliacyjnych i marketerów zrozumienie działania web crawlerów ma bezpośredni wpływ na sukces biznesowy. Boty decydują o widoczności stron produktowych, treści porównawczych i materiałów promocyjnych w wynikach wyszukiwania. Gdy użytkownicy PostAffiliatePro optymalizują swoje strony afiliacyjne pod kątem crawlowania, zwiększają szanse na odkrycie ich treści przez wyszukiwarki i pojawienie się na odpowiednie słowa kluczowe. Ta organiczna widoczność przyciąga wartościowy ruch do ofert afiliacyjnych, zwiększając szanse konwersji i zyski z prowizji.
Sieci afiliacyjne korzystają z crawlowania na wiele sposobów. Crawlery wyszukiwarek pomagają dystrybuować treści afiliacyjne w sieci, zwiększając świadomość marki i zasięg. Boty umożliwiają też porównywarkom cen i agregatorom treści wykrywanie i prezentowanie produktów afiliacyjnych, generując dodatkowe źródła ruchu. Jednocześnie marketerzy muszą być świadomi zagrożenia ze strony złośliwych crawlerów i scraperów, które mogą kopiować treści afiliacyjne lub powodować fraudy kliknięciowe. Wdrożenie właściwych limitów, systemów wykrywania botów i ochrony treści pozwala chronić integralność sieci afiliacyjnej przy jednoczesnym umożliwieniu działania legalnym crawlerom.
PostAffiliatePro oferuje kompleksowe narzędzia do śledzenia i raportowania, które doskonale uzupełniają optymalizację pod kątem crawlerów. Zapewniając prawidłowe indeksowanie Twoich treści afiliacyjnych, w połączeniu z zaawansowanym śledzeniem i analizą PostAffiliatePro, możesz zmaksymalizować widoczność oraz zyski swojej sieci afiliacyjnej. System śledzenia prowizji w czasie rzeczywistym oraz inteligentne raportowanie pomagają zrozumieć, które kanały afiliacyjne przynoszą najcenniejszy ruch, pozwalając Ci skutecznie optymalizować strategię sieciową.
Tak jak web crawlery systematycznie odkrywają i indeksują treści, PostAffiliatePro systematycznie śledzi i optymalizuje Twoje relacje afiliacyjne. Nasza platforma oferuje śledzenie w czasie rzeczywistym, kompleksowe raportowanie oraz inteligentne zarządzanie prowizjami, aby pomóc Ci zbudować prosperującą sieć afiliacyjną.
Crawlery gromadzą dane i informacje z internetu, odwiedzając strony i czytając ich zawartość. Dowiedz się o nich więcej.
Pająki to boty stworzone do spamu, które mogą sprawiać wiele problemów Twojej firmie. Dowiedz się więcej o nich w artykule.
Wyszukiwarka to oprogramowanie stworzone, aby ułatwić użytkownikom wyszukiwanie w internecie. Przeszukuje miliony stron i dostarcza najbardziej trafne wyniki....
Dołącz do naszej społeczności zadowolonych klientów i zapewnij doskonałą obsługę klienta dzięki PostAffiliatePro.
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.