
SEO pająki: Dlaczego są ważne dla Twojej strony
Pająki to boty stworzone do spamu, które mogą sprawiać wiele problemów Twojej firmie. Dowiedz się więcej o nich w artykule.
4 min czytania
SEO
DigitalMarketing
+3
Dowiedz się, dlaczego roboty internetowe nazywane są pająkami, jak działają i jaką pełnią kluczową rolę w indeksowaniu wyszukiwarek. Poznaj techniczne mechanizmy działania web crawlerów w 2025 roku.
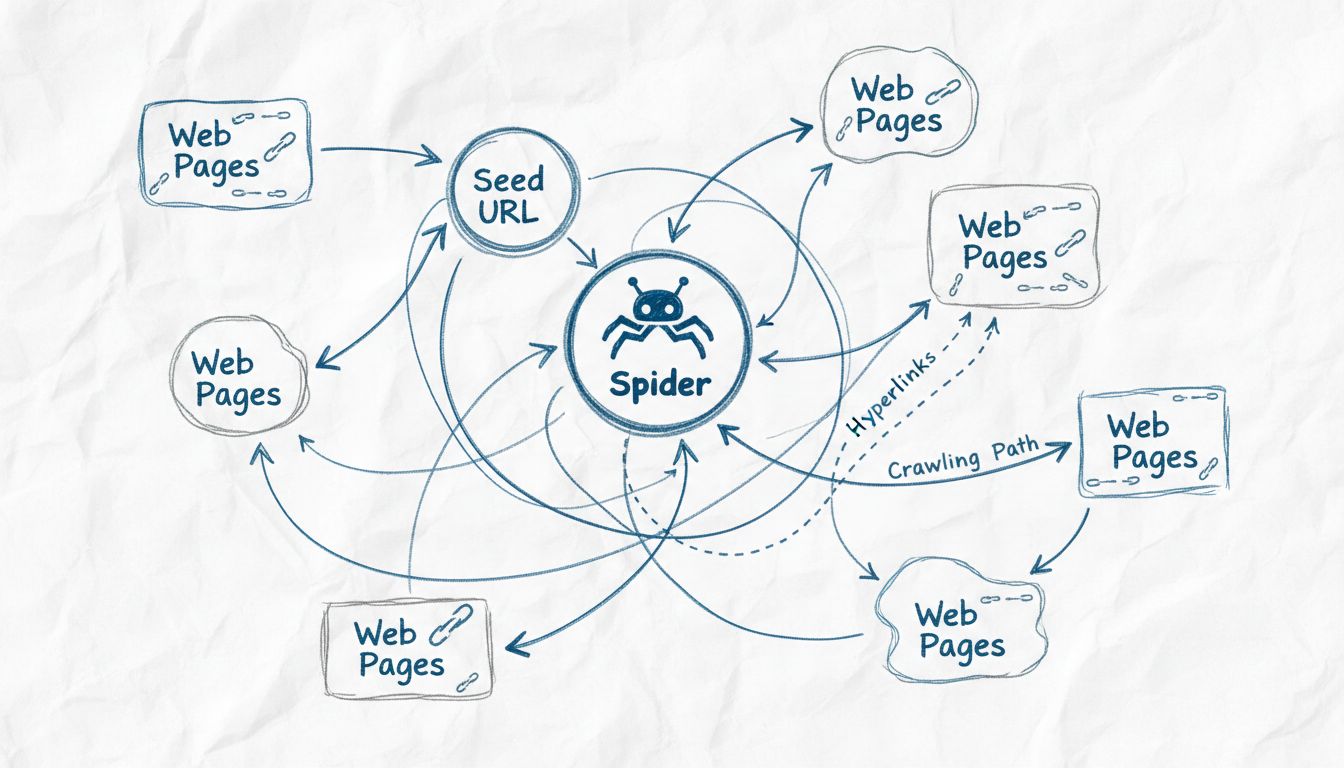
Roboty internetowe nazywane są pająkami, ponieważ systematycznie przeczesują sieć, podążając za linkami z jednej strony na drugą, podobnie jak pająk porusza się po swojej sieci. Określenie 'pająk' trafnie oddaje charakter tych automatycznych botów, które przemierzają połączoną sieć stron internetowych w celu odkrywania, indeksowania i organizowania treści dla wyszukiwarek.
Określenie „pająk” w kontekście robotów internetowych pochodzi z trafnej metafory porównującej sposób, w jaki te automatyczne boty przemierzają internet, do tego, jak prawdziwy pająk porusza się po swojej sieci. Tak jak pająk tka misterną sieć, aby zbierać i organizować informacje o swoim otoczeniu, tak roboty internetowe przemierzają połączoną sieć hiperłączy w World Wide Web, by odkrywać, analizować i porządkować treści cyfrowe. Metafora ta jest szczególnie trafna, ponieważ oba te byty działają systematycznie w złożonych sieciach, podążając ścieżkami do nowych miejsc i gromadząc informacje. To nazewnictwo tak mocno zakorzeniło się w technologii, że terminy „pająk”, „crawler” i „bot” są dziś używane zamiennie w rozmowach o technologii indeksowania sieci. Wizualne i koncepcyjne podobieństwo między siecią pająka a strukturą internetu sprawia, że ta terminologia jest zarówno intuicyjna, jak i łatwa do zapamiętania – zarówno dla specjalistów, jak i zwykłych użytkowników.
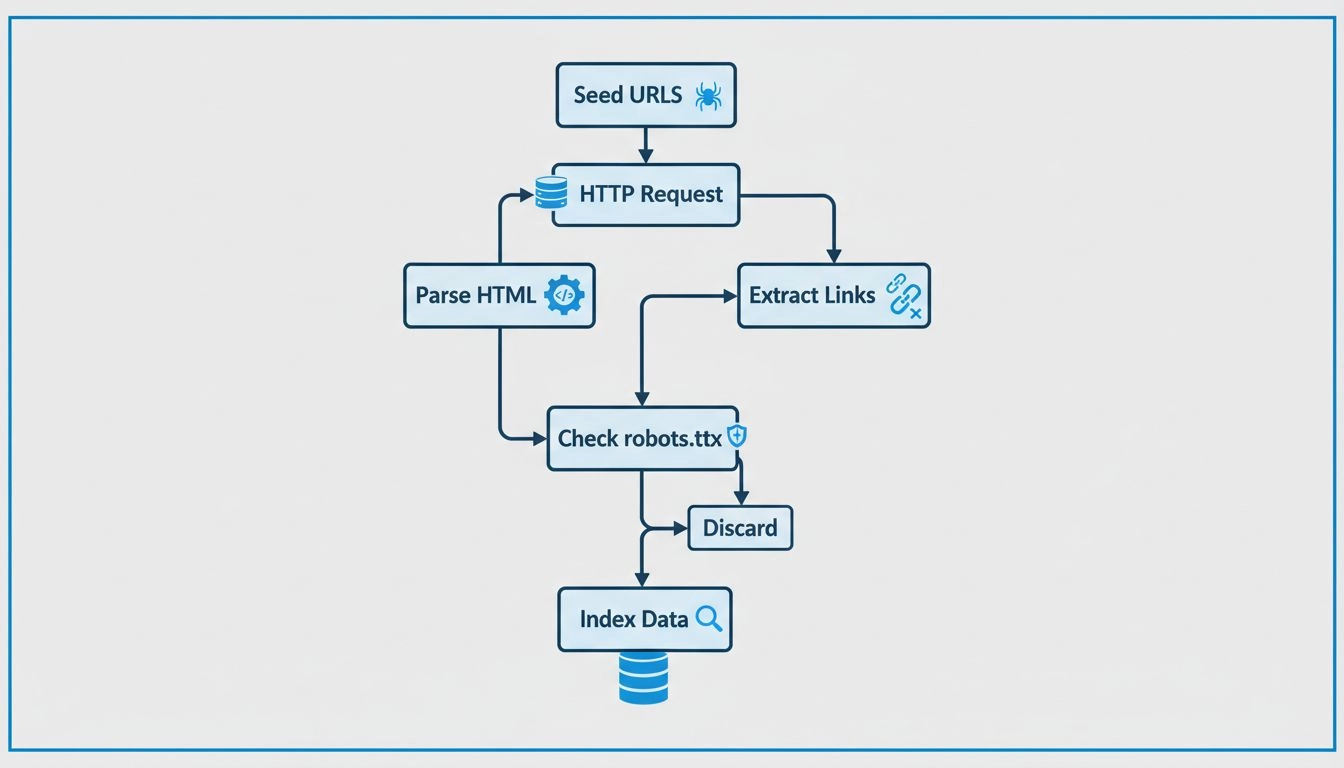
Pająki internetowe działają według zaawansowanego, ale systematycznego procesu, który rozpoczyna się od pojedynczego punktu wejścia, zwanego „seed URL”. Z tej lokalizacji początkowej pająk analizuje kod HTML strony internetowej, wyodrębniając wszystkie hiperłącza obecne na stronie. Następnie podąża za tymi linkami do nowych stron, powtarzając ten proces nieustannie, by poszerzać zasięg w sieci. Takie metodyczne podejście pozwala pająkom odkrywać miliony połączonych stron bez ręcznego zarządzania lub interwencji człowieka. Pająk utrzymuje tzw. „crawl frontier”, czyli kolejkę adresów URL, które zostały odkryte, ale jeszcze nie odwiedzone. Na podstawie określonych polityk i algorytmów crawlowania pająk ustala priorytety odwiedzania kolejnych adresów, biorąc pod uwagę takie czynniki jak ważność strony, częstotliwość aktualizacji oraz istotność dla celów indeksowania wyszukiwarki.
Skonfiguruj zaawansowane śledzenie w kilka minut. Karta kredytowa nie jest wymagana.
Współczesne pająki internetowe opierają się na zaawansowanej architekturze technicznej, która umożliwia im efektywne przetwarzanie ogromnych ilości danych. Główne komponenty robota sieciowego to system zarządzania kolejką adresów URL (frontier), który organizuje i ustala priorytety dla crawlowania; mechanizm pobierania, który szybko ściąga zawartość stron; silnik parsowania, który wydobywa linki i metadane z HTML; oraz system indeksowania, w którym przechowywane są przetworzone informacje do późniejszego wyszukiwania. Pająki muszą również stosować polityki uprzejmości, aby nie przeciążać serwerów zbyt dużą liczbą żądań, polityki ponownych odwiedzin decydujące o tym, jak często strony powinny być ponownie crawl’owane, oraz polityki selekcji, które określają, jakie linki są najbardziej wartościowe do śledzenia. Współczesne pająki potrafią obsługiwać treści generowane przez JavaScript i AJAX, choć nadal priorytetowo traktują standardowy HTML dla niezawodnego odkrywania treści. Rozproszony charakter dzisiejszego crawl’owania oznacza, że duże pająki działają równolegle na wielu serwerach, co pozwala im przeszukiwać różne strony jednocześnie i znacznie zwiększać ogólną wydajność oraz zasięg.
Choć terminy „pająk” i „crawler” często używane są zamiennie, warto wiedzieć, że oznaczają tę samą technologię, ale z różnym nazewnictwem. Jednak pająki internetowe znacząco różnią się od scraperów, z którymi bywają mylone. Główna różnica leży w celu i zakresie działania: roboty/crawlery zbierają ogólne informacje o stronach internetowych i ich strukturze, podążając szeroko po sieci, by budować kompleksowe indeksy. Pająki, gdy używane są przez wyszukiwarki, skupiają się na indeksowaniu treści tekstowych, by uczynić je możliwymi do wyszukania i odnalezienia. Scraperzy natomiast to precyzyjne narzędzia zaprojektowane do wyciągania konkretnych danych ze stron, takich jak ceny produktów, dane kontaktowe czy opinie – zazwyczaj z konkretnych stron lub typów danych, a nie z całego internetu. Ponadto crawlery i pająki z reguły respektują pliki robots.txt i regulaminy stron, podczas gdy scraperzy często działają bez takich ograniczeń. Zrozumienie tych różnic jest kluczowe dla właścicieli i twórców stron, którzy chcą zarządzać tym, jak ich treści są indeksowane przez automatyczne systemy.
Bądź pierwszym, który dowie się o nowych funkcjach i aktualizacjach produktu.
Pająki internetowe są absolutnie fundamentalne dla działania wyszukiwarek i wartości, jaką dają użytkownikom na całym świecie. Bez ciągłego crawl’owania i indeksowania treści przez pająki, wyszukiwarki nie miałyby informacji o tym, jakie strony istnieją, co się na nich znajduje i na ile są istotne dla zapytań użytkowników. Podczas crawl’owania strony pająk ocenia wiele czynników, w tym strukturę strony, istotność treści, użycie słów kluczowych i sygnały dotyczące doświadczenia użytkownika. Te informacje są następnie przechowywane w ogromnych indeksach, z których wyszukiwarka korzysta, by dopasować zapytania użytkowników do najbardziej trafnych wyników. Jakość i częstotliwość crawl’owania przez pająki bezpośrednio wpływa na to, jak szybko nowe treści pojawiają się w wynikach wyszukiwania i jak dokładnie wyszukiwarki mogą pozycjonować strony. Wyszukiwarki takie jak Google, Bing, Baidu czy Yahoo posiadają własne, dedykowane boty-pająki – odpowiednio Googlebot, Bingbot, Baiduspider i Slurp – każdy z unikalnymi algorytmami oraz strategiami crawl’owania dostosowanymi do swojej wyszukiwarki i jej użytkowników.
| Bot-pająk | Wyszukiwarka | Główna funkcja | Strategia crawlowania | Kluczowe cechy |
|---|---|---|---|---|
| Googlebot | Indeksowanie stron do Google Search | Rozproszone crawlowanie, warianty mobilny i desktopowy | Obsługuje JavaScript, priorytet mobile-first, respektuje budżet crawlowania | |
| Bingbot | Microsoft Bing | Indeksowanie stron do Bing Search | Równoległe crawlowanie na wielu serwerach | Efektywne użycie przepustowości, respektuje robots.txt, obsługuje różne typy treści |
| Baiduspider | Baidu | Indeksowanie stron do Baidu Search | Optymalizacja pod treści chińskie | Specjalizacja w treściach azjatyckich, obsługuje chiński uproszczony i tradycyjny |
| DuckDuckBot | DuckDuckGo | Indeksowanie stron dla wyszukiwania prywatnego | Uprzejme crawlowanie z naciskiem na prywatność | Minimalna zbiórka danych, respektuje preferencje użytkowników dotyczące prywatności |
| YandexBot | Yandex | Indeksowanie stron do Yandex Search | Rozproszone crawlowanie, optymalizacja regionalna | Optymalizacja pod treści rosyjskie i Europy Wschodniej |
Właściciele stron mają do dyspozycji wiele narzędzi i strategii, by zoptymalizować sposób, w jaki pająki crawl’ują i indeksują ich treści. Stworzenie kompleksowego pliku sitemap.xml daje pająkom wyraźną mapę wszystkich stron, które powinny być zaindeksowane, co znacząco poprawia efektywność crawl’owania i gwarantuje, że żadne ważne strony nie zostaną pominięte. Optymalizacja metatagów, w tym tytułów i opisów, pomaga pająkom zrozumieć zawartość strony i poprawia sposób, w jaki strony wyświetlają się w wynikach wyszukiwania. Poprawna konfiguracja pliku robots.txt pozwala właścicielom stron kierować pająki do istotnych treści oraz z dala od tych, które nie powinny być indeksowane, takich jak panele administracyjne czy powielone treści. Regularna aktualizacja i dodawanie nowych treści zachęca pająki do częstszych wizyt, co utrzymuje indeksy na bieżąco i poprawia widoczność strony w wyszukiwarkach. Właściciele powinni także zadbać o przejrzystą i logiczną architekturę strony oraz hierarchiczną nawigację, która ułatwia pająkom odkrywanie wszystkich podstron. Poprawa szybkości ładowania stron jest kluczowa, ponieważ pająki mają ograniczony budżet crawl’owania – im szybciej ładuje się strona, tym więcej treści pająk może przeindeksować w ramach tego budżetu.
Pomimo zaawansowania, pająki internetowe napotykają na wiele wyzwań technicznych, które mogą ograniczać ich skuteczność. Dynamiczne treści generowane przez JavaScript stanowią istotną przeszkodę, gdyż nie wszystkie pająki potrafią wykonać kod JavaScript i zobaczyć stronę tak, jak użytkownik. Ograniczenia szybkości narzucane przez strony www ograniczają liczbę żądań, jakie pająk może wykonać w określonym czasie, co może uniemożliwić pełne zindeksowanie dużych serwisów. CAPTCHY i inne zabezpieczenia antybotowe mogą blokować dostęp do treści, choć legalne boty wyszukiwarek są zwykle dodawane do białych list. Powielone treści pod różnymi adresami URL dezorientują pająki, która wersja powinna być indeksowana i pozycjonowana, co może osłabiać widoczność strony. Pułapki crawl’ujące – zamierzone lub przypadkowe pętle w strukturze strony – mogą marnować zasoby pająka i zużywać budżet crawl’owania bez efektywnego indeksowania. Ponadto lawinowy wzrost ilości treści w internecie sprawia, że pająki nie są w stanie przeindeksować wszystkiego, dlatego wykorzystują zaawansowane algorytmy do priorytetyzacji najważniejszych treści. Strony chronione hasłem czy wymagające logowania pozostają w większości niedostępne dla publicznych pająków, co ogranicza indeksowanie treści prywatnych lub tylko dla członków.
Technologia pająków internetowych nieustannie się rozwija wraz z rozrostem i komplikacją internetu. Nowoczesne pająki coraz lepiej radzą sobie z zaawansowanymi technologiami webowymi, w tym aplikacjami jednostronicowymi (SPA), progresywnymi aplikacjami webowymi (PWA) oraz dynamicznym renderowaniem treści. Sztuczna inteligencja i uczenie maszynowe są coraz częściej integrowane z algorytmami pająków, by lepiej rozumieć kontekst treści, intencje użytkownika i jakość strony. Rozwój generatywnej AI stawia nowe wymagania przed crawl’owaniem sieci, ponieważ systemy AI potrzebują stale aktualnych, istotnych i wiarygodnych informacji. Firmowe roboty webowe stają się coraz bardziej zaawansowane, umożliwiając przedsiębiorstwom crawl’owanie własnych stron na potrzeby wewnętrznych wyszukiwarek, zarządzania treścią czy monitorowania wydajności. Rosnące rozmiary i złożoność stron wymuszają coraz większy nacisk na efektywność crawl’owania – pająki wdrażają coraz sprytniejsze algorytmy priorytetyzacji, by maksymalizować wartość każdej wizyty. Kwestie prywatności także wpływają na rozwój pająków, z coraz większym naciskiem na respektowanie prywatności użytkowników przy jednoczesnym skutecznym odkrywaniu i indeksowaniu treści. W najbliższych latach pająki internetowe staną się jeszcze inteligentniejsze i wydajniejsze, wykorzystując zaawansowane technologie do poruszania się po coraz bardziej złożonym cyfrowym krajobrazie, przy zachowaniu zgodności z politykami stron oraz ochroną prywatności użytkowników.
Tak jak pająki internetowe systematycznie przeszukują i indeksują całą sieć, PostAffiliatePro systematycznie śledzi i optymalizuje każdą relację partnerską w Twojej sieci. Nasza zaawansowana technologia śledzenia gwarantuje, że żadna prowizja nie zostanie pominięta, a żadna okazja nie zostanie przeoczona.
Pająki to boty stworzone do spamu, które mogą sprawiać wiele problemów Twojej firmie. Dowiedz się więcej o nich w artykule.
Dowiedz się, jak działają web crawlery – od adresów początkowych po indeksowanie. Poznaj techniczny proces, typy crawlerów, zasady robots.txt oraz wpływ crawler...
Crawlery gromadzą dane i informacje z internetu, odwiedzając strony i czytając ich zawartość. Dowiedz się o nich więcej.
Dołącz do naszej społeczności zadowolonych klientów i zapewnij doskonałą obsługę klienta dzięki PostAffiliatePro.
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.